回到主页
目录
FAST GRAPH REPRESENTATION LEARNING WITH PYTORCH GEOMETRIC
本篇论文发表在ICLR 2019 (RLGM Workshop on Representation Learning on Graphs and Manifolds),该论文也是Open Data Science总结2019第一季度的深度学习十佳论文排名第一的论文
参考资料:https://tech.sina.com.cn/csj/2019-05-07/doc-ihvhiews0329883.shtml和https://medium.com/@ODSC/best-deep-learning-research-of-2019-so-far-7bea0ed22e38
第一作者:Matthias Fey德国多特蒙德工业大学博二学生

Abstract:
- 介绍了PyTorch Geometric,一个用于深度学习不规则结构(图、点云和流形)为输入数据的库,该库基于PyTorch
- 除了一般的图数据结构和处理方法之外,它还包含了关系学习和3D数据处理领域中最近发表的各种方法
- PyTorch Geometric通过使用稀疏GPU加速、提供专用CUDA内核以及为不同大小的输入示例引入高效的小批量处理,实现了高数据吞吐量
- 本文详细地介绍了该库,并对在相同条件下实现的方法进行了全面的比较研究
1. INTRODUCTION(介绍)
首先说明图神经网络的背景意义:
- 最近,图神经网络(GNNs)作为一种强大的表示学习方法出现在图、点云和流形数据结构上(Bronstein et al., 2017
Geometric deep learning: going beyond Euclidean data; Kipf & Welling, 2017Semi-Supervised Classification with Graph Convolutional Networks) - 与正则域上的卷积层和池化层的概念类似,GNN能够(层次结构地)通过传递、转换和聚合信息来提取局部嵌入信息(Bronstein et al.,2017
Geometric deep learning: going beyond Euclidean data; Gilmer et al.,2017Neural Message Passing for Quantum Chemistry(该文章论文中引用多次,值得注意!); Battaglia et al., 2018Relational inductive biases, deep learning, and graph networks; Ying et al., 2018Hierarchical Graph Representation Learning with Differentiable Pooling; Morris et al., 2019Weisfeiler and Leman Go Neural: Higher-order Graph Neural Networks)
1 《关系归纳偏置、深度学习和图网络》(详情请点击本行)
为什么“图网络”是近年来人工智能流行的趋势?
该论文是DeepMind联合谷歌大脑、MIT等机构27位作者发表重磅论文,提出“图网络”(Graph network),将端到端学习与归纳偏置相结合,有望解决深度学习无法进行关系推理的问题。
背景简介:
1. 人工智能、机器学习、深度学习三者的关系
1.1 为什么人工智能、机器学习、深度学习三者的关系总让人混淆?
有人说 AI 是一门最悲剧的学科,因为每当它的一个子领域发展得像模像样之后,就立马自立门户,从此和 AI “再无瓜葛”了, (Machine Learning 大概要算是最新的一个典型吧。这就让人有点奇怪,比如说数学,分门别类总算是够多了吧?可以不管怎么分,大家兄弟姐妹也都还承认自己是叫“数学”的。那 AI呢?这里有很大一部分是它自身定位的问题。)
- AI 在一开始定了一个过高的目标,几十年后,发现情况并不像当年那么乐观,却又有些下不了台了
- 这个时候,AI 的一些旁枝或者子领域果断放下面子, 丢掉了那个近乎玄幻的目标,逐渐发展成为“正常”的学科
- Machine Learning 作为离家出走的典型,虽然名字里带了 Learning 一个词,让人乍一看觉得和 Intelligence 相比不过是换了个说法而已,然而事实上这里的 Learning 的意义要朴素得多。
- 回顾Machine Learning 的典型的流程就知道了:
- 与应用数学或者更通俗的数学建模有些类似,通常我们会有需要分析或者处理的数据,根据一些经验和一些假设,我们可以构建一个模型
- 这个模型会有一些参数(即使是非参数化方法,也是可以类似地看待的),根据数据来求解模型参数的过程,就叫做 Parameter Estimation ,或者 Model Fitting
- 但是搞机器学习的人,通常把它叫做 Learning (或者,换一个角度,叫 Training)——因为根据数据归纳出一个有用的模型, 这和我们人类“学习”的过程还是挺类似的吧
- 不过,如果抛开无聊的抠字眼游戏的话,我们可以看到,Machine Learning 已经抛弃了“智能”的高帽子, 它的目的就是要解决具体的问题——而并不关心是否是通过一种“智能”的方式类解决的
- 说到这里,其实我们构造模型就类似于写一个类,数据就是构造函数的参数,Learning 就是构造函数运行的过程,成功构造一个对象之后,我们就完成了学习
————张驰原
1.2 人工智能、机器学习、深度学习三者关系与对应发展时间
根据上一小节的介绍,下面这张关系图也就显而易见了:
如上图:
- 人工智能是最早出现的,也是最大、最外侧的同心圆
- 其次是机器学习,稍晚一点
- 最内侧,是深度学习, 当今人工智能大爆炸的核心驱动。
- 五十年代, 人工智能曾一度被极为看好
- 之后, 人工智能的一些较小的子集发展了起来。先是机器学习,然后是深度学习
- 深度学习又是机器学习的子集。深度学习造成了前所未有的巨大的影响。
具体来说:
- 1956年,几个计算机科学家相聚在达特茅斯会议(Dartmouth Conferences),提出了“人工智能”的概念
- 其后,人工智能就一直萦绕于人们的脑海之中,并在科研实验室中慢慢孵化
- 之后的几十年,人工智能一直在两极反转, 或被称作人类文明耀眼未来的预言;或者被当成技术疯子的狂想扔到垃圾堆里。坦白说,直到2012年之前,这两种声音还在同时存在
- 2012年Hinton课题组首次参加ImageNet图像识别大赛, 通过构建CNN的AlexNet一举夺得冠军,且碾压第二名 (SVM方法)
- 过去几年,尤其是2015年以来,人工智能开始大爆发。很大一部分是由于GPU的广泛应用, 使得并行计算变得更快、更便宜、更有效
- 当然,爆发也跟无限拓展的存储能力和骤然爆发的数据洪流(大数据) 的组合拳,也使得图像数据、文本数据、交易数据、映射数据全面海量爆发有关
参考资料:https://www.cnblogs.com/dadadechengzi/articles/6575767.html
2. 本论文的大背景及其意义
人工智能界有三个主要学派,符号主义(Symbolicism)、连接主义(Connectionism)、行为主义(Actionism)。
符号主义的起源,注重研究知识表达和逻辑推理。经过几十年的研究,目前这一学派的主要成果,一个是贝叶斯因果网络,另一个是知识图谱。
- 贝叶斯因果网络的旗手是Judea Pearl 教授,2011年的图灵奖获得者。但是据说 2017年 NIPS 学术会议上,老爷子演讲时,听众寥寥。2018年,老爷子出版了一本新书,“The Book of Why”,为因果网络辩护,同时批判深度学习缺乏严谨的逻辑推理过程
- 而知识图谱主要由搜索引擎公司,包括谷歌、微软、百度推动,目标是把搜索引擎,由关键词匹配,推进到语义匹配
连接主义的起源是仿生学,用数学模型来模仿神经元
- Marvin Minsky 教授因为对神经元研究的推动,获得了1969年图灵奖
- 把大量神经元拼装在一起,就形成了深度学习模型, 深度学习的旗手是 Geoffrey Hinton 教授,2018图灵奖获得者。深度学习模型最遭人诟病的缺陷,是不可解释
行为主义把控制论引入机器学习,最著名的成果是强化学习
- 强化学习的旗手是 Richard Sutton 教授。近年来Google DeepMind 研究员,把传统强化学习,与深度学习融合, 实现了 AlphaGo,战胜当今世界所有人类围棋高手
DeepMind 发表的这篇论文,提议把传统的贝叶斯因果网络和知识图谱,与深度强化学习融合, 并梳理了与这个主题相关的研究进展。
参考资料:https://blog.csdn.net/qq_32201847/article/details/80708193

转折说明图神经网络面临的一个挑战,引出本文研究对象:
- 然而,实现GNNs是一个挑战, 因为需要在高度稀疏和不规则的不同大小的数据上实现高GPU吞吐量。在这里,介绍PyTorch Geometric(PyG)
- 这是一个针对PyTorch(Paszke et al., 2017)
Automatic differentiation in PyTorch的几何深度学习扩展库,它利用专用CUDA内核实现了高性能。遵循一个简单的消息传递API,它将最近提出的大多数卷积和池化层融合到一个统一的框架中 - 该库中实现的所有方法都支持CPU和GPU计算,并遵循一个不可变的数据流范式,支持图形结构随时间的动态变化。PyG是在MIT许可下发布的,可以在GitHub上找到
- 它有完整的文档,并提供了相关的教程和示例作为起点进行学习
2 MIT许可相关资料图(详情请点击本行)
| pytorch | PyG | tensorflow/mxnet

2. OVERVIEW(总览)
数学符号:
- 使用代表图
- 代表个节点的特征矩阵
- 稀疏的邻接元组代表条边,其中将边索引编码为COOrdinate(COO) 格式。保存维边特征(可选的)。
基本数据结构:class Data(x=None, edge_index=None, edge_attr=None, y=None, pos=None, norm=None, face=None, **kwargs)
邻接聚合。 将卷积运算符推广到不规则域通常表示为邻域聚合或消息传递模式(Gilmer et al.,2017)Neural Message Passing for Quantum Chemistry

其中:
- 代表一个可微的排列不变函数(a differentiable, permutation invariant function)。例如:求和,求平均,取最大。
- 和代表可微函数,例如:多层感知机(Multilayer Perceptron)。
在实际应用中,可以通过对节点特征的聚集和分散以及在和函数上使用按照元素矢量化计算(vectorized element-wise computation)来实现,如图1所示。 虽然处理的是不规则结构的输入,但这种方案可以被GPU大大加速。相对于通过稀疏矩阵乘法实现,使用gather/ scatterts被证明对于低阶图和非合并输入是有利的, 并允许在聚合时集成中心节点和多维边缘信息。
作者提供了一个MessagePassing接口允许使用者快速和清晰的原型供大家创造新的研究思路。
为了使用该类,用户只需要定义如下方法:
- 函数,即
message方法 - 函数,即
update方法 - 聚合方案,即构造函数中的
aggr="add"("add", "mean" or "max") - 实现时、节点特征会自动映射到各自的源和目标节点,即构造函数中的
flow="source_to_target"("source_to_target" or "target_to_source")
3 MessagePassing源码分析(详情请点击本行)

import sys
import inspect
import torch
from torch_geometric.utils import scatter_
special_args = [
'edge_index', 'edge_index_i', 'edge_index_j', 'size', 'size_i', 'size_j'
] #用于存储需要特殊对待的参数字符串的名字
__size_error_msg__ = ('All tensors which should get mapped to the same source '
'or target nodes must be of same size in dimension 0.') #错误提示元组
# 下面根据python版本选择用于得到运行时函数参数列表的函数(传入函数名即可)
is_python2 = sys.version_info[0] < 3
getargspec = inspect.getargspec if is_python2 else inspect.getfullargspec
class MessagePassing(torch.nn.Module):
r"""Base class for creating message passing layers
.. math::
\mathbf{x}_i^{\prime} = \gamma_{\mathbf{\Theta}} \left( \mathbf{x}_i,
\square_{j \in \mathcal{N}(i)} \, \phi_{\mathbf{\Theta}}
\left(\mathbf{x}_i, \mathbf{x}_j,\mathbf{e}_{i,j}\right) \right),
where :math:`\square` denotes a differentiable, permutation invariant
function, *e.g.*, sum, mean or max, and :math:`\gamma_{\mathbf{\Theta}}`
and :math:`\phi_{\mathbf{\Theta}}` denote differentiable functions such as
MLPs.
See `here <https://rusty1s.github.io/pytorch_geometric/build/html/notes/
create_gnn.html>`__ for the accompanying tutorial.
Args:
aggr (string, optional): The aggregation scheme to use
(:obj:`"add"`, :obj:`"mean"` or :obj:`"max"`).
(default: :obj:`"add"`)
flow (string, optional): The flow direction of message passing
(:obj:`"source_to_target"` or :obj:`"target_to_source"`).
(default: :obj:`"source_to_target"`)
"""
def __init__(self, aggr='add', flow='source_to_target'):
super(MessagePassing, self).__init__()
# 存储聚合方案的类变量aggr
self.aggr = aggr
assert self.aggr in ['add', 'mean', 'max']
# 存储图中节点映射方向的类变量flow
self.flow = flow
assert self.flow in ['source_to_target', 'target_to_source']
# 得到message实际传入的参数变量名并存储在__message_args__中
self.__message_args__ = getargspec(self.message)[0][1:]
#筛选出变量名中的特殊参数名,即:'edge_index', 'edge_index_i', 'edge_index_j', 'size', 'size_i', 'size_j'
#并且编号为元组的列表,eg:[(0,edge_index),(1,edge_index_j)] etc.
self.__special_args__ = [(i, arg)
for i, arg in enumerate(self.__message_args__)
if arg in special_args]
# 除去__message_args__中的特殊参数名
self.__message_args__ = [
arg for arg in self.__message_args__ if arg not in special_args
]
# 得到update实际传入的参数变量名并存储在__update_args__中
self.__update_args__ = getargspec(self.update)[0][2:]
def propagate(self, edge_index, size=None, **kwargs):
r"""The initial call to start propagating messages.
Args:
edge_index (Tensor): The indices of a general (sparse) assignment
matrix with shape :obj:`[N, M]` (can be directed or
undirected).
size (list or tuple, optional): The size :obj:`[N, M]` of the
assignment matrix. If set to :obj:`None`, the size is tried to
get automatically inferrred. (default: :obj:`None`)
**kwargs: Any additional data which is needed to construct messages
and to update node embeddings.
"""
# 得到图分配矩阵的大小,默认为None
size = [None, None] if size is None else list(size)
assert len(size) == 2
# 根据构造时类变量flow的参数选择字典ij的内容, eg: 'target_to_source'时是{"_i": 0, "_j": 1}
i, j = (0, 1) if self.flow == 'target_to_source' else (1, 0)
ij = {"_i": i, "_j": j}
message_args = []
for arg in self.__message_args__: #遍历message实际传入的参数
if arg[-2:] in ij.keys(): #如果参数后两个字符串是"_i"或者 "_j"
tmp = kwargs.get(arg[:-2], None) #得到包含"_i"或"_j"的参数名的前面的字符串的变量名对应的变量值
if tmp is None: # pragma: no cover
message_args.append(tmp)
else: #如果tmp包含内容的话,则根据self.flow得到需要处理的数据
idx = ij[arg[-2:]]
if isinstance(tmp, tuple) or isinstance(tmp, list):
assert len(tmp) == 2
if tmp[1 - idx] is not None:
if size[1 - idx] is None:
size[1 - idx] = tmp[1 - idx].size(0)
if size[1 - idx] != tmp[1 - idx].size(0):
raise ValueError(__size_error_msg__)
tmp = tmp[idx]
if size[idx] is None:
size[idx] = tmp.size(0)
if size[idx] != tmp.size(0):
raise ValueError(__size_error_msg__)
tmp = torch.index_select(tmp, 0, edge_index[idx])
message_args.append(tmp)
else: #如果参数后两个字符串不是"_i"或者 "_j"
message_args.append(kwargs.get(arg, None)) #直接从kwargs挑出对应参数的值附加到message_args中
size[0] = size[1] if size[0] is None else size[0]
size[1] = size[0] if size[1] is None else size[1]
# 关键字参数列表kwargs中加入必选参数
kwargs['edge_index'] = edge_index
kwargs['size'] = size
#message_args 中加入特殊参数
for (idx, arg) in self.__special_args__:
if arg[-2:] in ij.keys():
message_args.insert(idx, kwargs[arg[:-2]][ij[arg[-2:]]])
else:
message_args.insert(idx, kwargs[arg])
#update_args 中保存update函数的传入参数
update_args = [kwargs[arg] for arg in self.__update_args__]
# 这一块对应论文中的图片!
out = self.message(*message_args)
#下面这个函数使用https://github.com/rusty1s/pytorch_scatter包中的方法,该方法解释如下:
#一个小型扩展库,其中包含用于PyTorch的高度优化的稀疏更新(scatter)操作,
#这些操作在主包(Pytorch)中没有。散点运算可以粗略地描述为基于给定的“群指数”张量的约简运算。


out = scatter_(self.aggr, out, edge_index[i], dim_size=size[i]) #该论文的优化点
out = self.update(out, *update_args)
return out
def message(self, x_j): # pragma: no cover
r"""Constructs messages in analogy to :math:`\phi_{\mathbf{\Theta}}`
for each edge in :math:`(i,j) \in \mathcal{E}`.
Can take any argument which was initially passed to :meth:`propagate`.
In addition, features can be lifted to the source node :math:`i` and
target node :math:`j` by appending :obj:`_i` or :obj:`_j` to the
variable name, *.e.g.* :obj:`x_i` and :obj:`x_j`."""
return x_j
def update(self, aggr_out): # pragma: no cover
r"""Updates node embeddings in analogy to
:math:`\gamma_{\mathbf{\Theta}}` for each node
:math:`i \in \mathcal{V}`.
Takes in the output of aggregation as first argument and any argument
which was initially passed to :meth:`propagate`."""
return aggr_out
A. 几乎所有最近提出的邻域聚合函数都可以使用这个接口,包括(但不限于)已经集成到PyG中的方法:
-
*对于学习任意图结构,实现了GCN(Kipf & Welling,2017)
Semi-Supervised Classification with Graph Convolutional Networks(GCNConv函数)
其中表示插入自循环的邻接矩阵,是它的对角度矩阵。 -
*及其简化版本SGC(Wu et al.2019)
Simplifying Graph Convolutional Networks(SGConv函数)
其中表示插入自循环的邻接矩阵,是它的对角度矩阵。 -
*谱切比雪夫卷积(Defferrard et al., 2016)
Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering(ChebConv函数)
其中递归的由下式给出:
表示缩放归一化后的拉普拉斯行列式 -
*ARMA滤波器卷积(Bianchi et al., 2019)
Graph Neural Networks with convolutional ARMA filters(ARMAConv函数)
其中递归的由下式给出:
其中表示修改后的拉普拉斯行列式 -
GraphSAGE(Hamilton et al., 2017)
Inductive Representation Learning on Large Graphs(SAGEConv函数)
-
基于注意力机制的GAT(Veličković et al.,2018)
Graph Attention Networks(GATConv函数)
其中注意系数根据下式计算得出:
-
AGNN (Thekumparampil et al., 2018)
Attention-based Graph Neural Network for Semi-supervised Learning(AGNNConv函数)
其中传播矩阵根据下式计算得出:
其中为可训练的参数 -
图同构网络GIN(Xu et al., 2019)
How Powerful are Graph Neural Networks?(GINConv函数)
其中表示神经网络,即一个多层感知机。 -
神经预测的近似个性化传播网络APPNP(Klicpera et al., 2019)
Predict then Propagate: Graph Neural Networks meet Personalized PageRank(APPNP函数)(该方法似乎尝试解决邻接数尺寸,值得注意!ICLR2019)
其中表示插入自循环和的邻接矩阵,是它的对角度矩阵。 -
动态邻域聚合操作DNA(Fey, 2019)
Just Jump: Dynamic Neighborhood Aggregation in Graph Neural Networks(DNAConv函数)
基于(多头)点乘注意力机制:
其中分别表示查询、键和值信息的(分组)投影矩阵。是非可训练版本torch_geometric.nn.conv.GCNConv的实现 -
在有符号网络中学习的带符号算子(Derr et al., 2018)
Signed Graph Convolutional Network(SignedGCN函数)
如果first_aggr被设置为True,并且
否则。在first_aggr为False的情况下,层期望x是一个张量,其中x[:,:in_channels]表示正节点特征,x[:,in_channels:]表示负节点特征。
B. 用于学习点云、流形和具有多维边缘特征图形的方法:
-
PyG中提供了相关GCN操作
- (Schlichtkrull et al., 2018)
Modeling Relational Data with Graph Convolutional Networks(RGCNConv函数)
其中表示关系集,即边类型。边类型需要是一维的
torch.long张量。其为每一个边存储一个关系标识符。-
PointNet++(Qi et al., 2017)
PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space(PointConv函数)
其中和代表神经网络,即多层感知机。代表每一个点的位置 -
PointCNN(Li et al., 2018)
PointCNN: Convolution On X-Transformed Points(XConv函数)
其中和分别代表可训练滤波器和相邻的点的位置。和代表神经网络,即多层感知机。其中将每个点单独提升到高维空间,就算出了基于所有领接点的X-Transformed矩阵。
- (Schlichtkrull et al., 2018)
-
连续的基于核的方法
-
(Gilmer et al.,2017)
Neural Message Passing for Quantum Chemistry(NNConv函数)
其中代表神经网络,即多层感知机。 -
(Simonovsky & Komodakis, 2017)
Dynamic Edge-Conditioned Filters in Convolutional Neural Networks on Graphs(voxel_grid函数)
论文中描述的立体像素网格池化层,它在一个点云上覆盖一个用户定义大小的规则网格,并将所有点集中在同一个像素内。 -
MoNet (Monti et al., 2017)
Geometric deep learning on graphs and manifolds using mixture model CNNs(GMMConv函数)
其中:
表示基于可训练均值向量的加权函数以及对角协方差矩阵 -
SplineCNN (Fey et al., 2018)
SplineCNN: Fast Geometric Deep Learning with Continuous B-Spline Kernels(SplineConv函数)
其中表示在加权b样条张量乘积基上定义的核函数。
-
-
边卷积操作EdgeCNN(Wang et al. 2018)
Dynamic Graph CNN for Learning on Point Clouds(EdgeConv函数)
其中代表神经网络,即多层感知机。
C. 除了以上这些操作符,PyG还提供高等级级的函数实现:
- 最大化互信息(Veličković et al., 2019)
Deep graph infomax.(DeepGraphInfomax函数) - 自编码图
- (Kipf & Welling, 2016)
Variational Graph Auto-Encoders(InnerProductDecoder函数) - (Pan et al., 2018)
Adversarially Regularized Graph Autoencoder for Graph Embedding(ARGA函数和ARGVA函数)
- (Kipf & Welling, 2016)
- 聚合跳知识(aggregating jumping knowledge) (Xu et al., 2018)
Representation Learning on Graphs with Jumping Knowledge Networks(JumpingKnowledge函数) - 预测知识图中的时间事件(Jin et al., 2019)
Recurrent Event Network for Reasoning over Temporal Knowledge Graphs(RENet函数)
全局池化 PyG还支持图形级输出,而不是节点级输出,它支持各种读取函数,如全局添加、平均值或最大池。还提供更复杂的方法:
-
集合到集合(Vinyals et al., 2016)
Order Matters: Sequence to sequence for sets(Set2Set函数)
其中代表输出层,其维度是输入的两倍。 -
排序池化层 (Zhang et al., 2018)
An End-to-End Deep Learning Architecture for Graph Classification(global_sort_pool函数) -
*全局软注意力机制层 (Li et al., 2016)
Gated Graph Sequence Neural Networks(GatedGraphConv函数和GlobalAttention函数)(AAAI 19-用户行为分析使用这篇论文的方法)
其中,代表神经网络,即多层感知机。
层次池化 为了进一步提取层次信息并允许更深层次的GNN模式,可以以空间或数据依赖的方式应用各种池方法。目前提供了以下实现:
- 贪婪的聚类算法Gracluss (Dhillon et al., 2007)
Weighted Graph Cuts without Eigenvectors: A Multilevel Approach(graclus函数),即:选择一个未标记的顶点,并将其与它的一个未标记的邻居点进行匹配(从而最大化其边缘权重)。其中GPU算法采用(Fagginger Auer & Bisseling,2011)论文中的方法。 - 立体像素网格池化层(voxel grid pooling)(Simonovsky & Komodakis, 2017)
Dynamic Edge-Conditioned Filters in Convolutional Neural Networks on Graphs(voxel_grid函数) - 迭代最远点采样算法(Qi et al., 2017)
PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space(fps函数) - k-NN或查询球图生成方法(K-NN or query ball graph generation)(Qi et al., 2017)
PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space以及(Wang et al. 2018)Dynamic Graph CNN for Learning on Point Clouds(knn_interpolate函数)
对于每一个位置为的点,它的插值特性根据下式给出:
其中代表的个邻近点。 - 可微池机制
- DiffPool (Ying et al., 2018)
Hierarchical Graph Representation Learning with Differentiable Pooling(dense_diff_pool函数)
基于密集学习任务。返回合并节点特征矩阵、粗化邻接矩阵和辅助链路预测目标 - top-k池 (Gao & Ji, 2018)
Graph U-Net以及 (Cangea et al., 2018)Towards Sparse Hierarchical Graph Classifiers(TopKPooling函数)
其中节点是基于一个可学习的投影评分来删除的。
- DiffPool (Ying et al., 2018)
小批量处理 PyG的框架通过自动创建单个(稀疏)块对角邻接矩阵和连接节点维中的特征矩阵,支持批量的多个图实例(大小可能不同)。因此,无需修改即可应用邻域聚合方法,因为断开连接的图之间不交换任何消息。此外,自动生成的赋值向量确保节点级别的信息不会跨图聚合,例如,当执行全局聚合操作符时。
数据集处理 PyG提供了一个一致的数据格式和易于使用的接口来创建和处理数据集,既适用于大型数据集,也适用于训练期间可以保存在内存中的数据集。为了创建新的数据集,用户只需要读取/下载他们的数据,并在各自的process方法中将其转换为PyG数据格式。此外,数据集可以通过使用transforms方法来修改,转换采用单独的图形并对其进行转换,例如,用于数据增强,用于使用合成结构图属性增强节点特征(Cai &Wang, 2018)A simple yet effective baseline for non-attributed graph classification(LocalDegreeProfile函数),从点云自动生成图或从网格中采样点云。
对于节点特征,其中。
PyG已经支持许多常见的基准数据集,这些数据集通常在文献中找到,它们在第一次实例化时自动下载并处理。其中提供了60多个图的核基准数据集https://ls11-www.cs.tu-dortmund.de/staff/morris/graphkerneldatasets:
- (Kersting et al., 2016),如,PROTEINS or IMDB-BINARY, the citation graphs Cora, CiteSeer
- PubMed and Cora-Full 来自论文(Sen et al., 2008; Bojchevski & Günnemann,2018)
- the Coauthor CS/Physics and Amazon Computers/Photo datasets 来自论文 Shchur et al. (2018)
- 分子数据集 QM7b, 来自论文(Montavon et al., 2013) 以及 QM9,来自论文(Ramakrishnan et al., 2014)
- 蛋白质相互作用图(protein-protein interaction graphs), 来自论文 Hamilton et al. (2017)
- 时间数据集,来自论文Bitcoin-OTC (Kumar et al., 2016), ICEWS (Boschee et al., 2015) and GDELT (Leetaru & Schrodt, 2013)
- 此外,PyG还提供嵌入式数据集比如:MNIST superpixels,其来自论文 (Monti et al., 2017), FAUST (Bogoet al., 2014), ModelNet10/40 (Wu et al., 2015), ShapeNet (Chang et al., 2015), COMA (Ranjan et al.,2018)
- PCPNet数据集,来自论文Guerrero et al. (2018).
3. EMPIRICAL EVALUATION(实证性评估)
通过对相同评价场景的综合比较研究,评价了所实现方法的正确性。所有使用过的数据集的描述和统计可以在附录b中找到。对于所有的实验,都尽可能地遵循相关论文的超参数设置。可以派生出单独的实验设置,并且可以从GitHub储存库中提供的代码复制出相应的组件。
半监督节点分类问题

本小节展示了半监督节点分类问题,见表一。实验分两块:
-
仿照论文Kipf & Welling, 2017
Semi-Supervised Classification with Graph Convolutional Networks)所描述的方法进行100次固定训练集/验证集/测试集拆分的数据进行实验并求得平均值 -
仿照论文Shchuret al. 2018
Pitfalls of Graph Neural Network Evaluation所描述的方法进行100次随机训练集/验证集/测试集拆分的数据,保证训练集上拆分时类别均匀分布,然后进行实验并求得平均值
几乎所有的实验都显示了各自论文报告结果的高可重复性。 然而,当使用随机数据分割时,所有模型的测试性能都更差。在实验中,APPNP操作(Klicpera et al., 2019)的性能一般最好,ARMA,SGC,GCN,GAT方法其次。
图分类问题
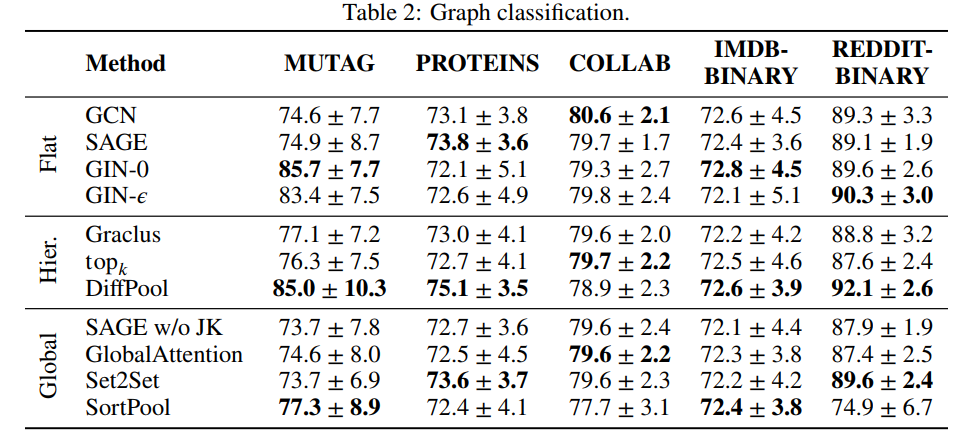
本小节展示了一些常见基准数据集进行10折交叉验证得到的平均精度(表2),具体设置如下:
- 随机抽取一个折数据作为验证集,只使用离散的节点特征
- 在没有给定节点属性的情况下,使用节点度的独热编码作为特征输入
- 对于所有的实验,我们使用全局平均算子来得到图的输出
- 受跳跃知识框架(Jumping Knowledge framework)(Xu et al., 2018)的启发,这里计算每个卷积层之后的图形级输出,并通过连接运算符将它们组合起来
- 为了评估(全局)池操作符,这里使用GraphSAGE操作符作为基线
- 在比较全局池操作符时,省略了跳跃知识(jumbing knowledge),因此这里展示了一个基于全局平均池的附加基线
- 对于每个数据集,相对验证集做如下调优:
- 隐藏单位的数量
- 层数
由于评估和网络架构进行了统一标准化,因此并不是所有的结果都与其对应论文中展示的值一致。例如:
- 除了DiffPool (Ying et al., 2018), (global)池操作符的性能并没有其对应的(flat)操作符预期的那么好,特别是当基线通过跳跃知识得到增强时(Xu et al., 2018)。然而,在这些简单的基准测试任务中,可能无法很好地反映更复杂方法的潜力(Cai &Wang, 2018)
- 在平GNN方法中,GIN层(Xu et al., 2019)的效果最好。
点云分类问题
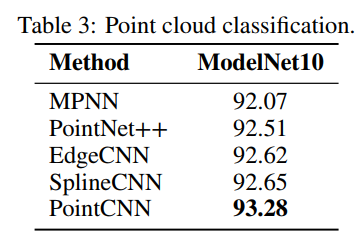
本小节评估不同的点云的方法ModelNet10(Wu et al ., 2015)并从网格表面均匀样本1024点基于面临区域(表3):
- 这里为每个模型使用了大约相同数量的参数
- 所有方法的性能几乎相同,PointCNN (Li et al., 2018)略有领先
- 得到这样一个事实,即所有操作方法都基于类似的原则,并且对于给定的任务可能具有相同的表达能力。
运行时实验

对多个数据模型对进行了多次实验:
- 用单个NVIDIA GTX 1080 Ti上训练200个批,然后得到整个训练过程的运行情况(表 4)
- 与深度图库(DGL) v0.2 (Wang et al., 2018a)的Degree Bucketing(DB)算法方法相比,PyG训练模型的速度快了40倍
- 使用聚集和分散优化(GS)内置到DGL内时的运行时算法也进行了比较,得出如果使用自己的优化稀疏的softmax内和算法,可以在GTA(Veličkovićet al ., 2018)算法上进一步提高的7倍的运行时的训练速度
4. ROADMAP AND CONCLUSION(技术路线及结论)
- 本文提出了一种用于图形、点云和流形快速表示学习的PyTorch几何框架
- 我们正积极努力进一步集成现有的方法,并计划将未来的方法快速集成到PyG的框架中
- 我们邀请所有的研究人员和软件工程师来一起合作,以扩大其应用范围
5. 附录
5.1 流形
注:此部分参考张驰原的博客(ICLR 2017 BestPaper/Mxnet(16K Star)主要开发者)
Manifold Learning 或者仅仅 Manifold 本身通常就听起来颇有些深奥的感觉,有时候经常会在 paper 里看到 嵌入在高维空间中的低维流形。不过如果并不是想要进行严格的理论推导的话,也可以从许多直观的例子得到一些感性的认识。
5.1.1 示例一
因为高维的数据对于我们这些可怜的低维生物来说总是很难以想像,所以最直观的例子通常都会是嵌入在三维空间中的二维或者一维流形。
比如说一块布,可以把它看成一个二维平面,这是一个二维的欧氏空间,现在我们(在三维)中把它扭一扭,它就变成了一个流形(当然,不扭的时候,它也是一个流形,欧氏空间是流形的一种特殊情况)。
所以,直观上来讲,一个流形好比是一个 维的空间,在一个 维的空间中 被扭曲之后的结果。 需要注意的是,流形并不是一个“形状”,而是一个“空间”,如果你觉得“扭曲的空间”难以想象,那么请再回忆之前一块布的例子。
广义相对论似乎就是把我们的时空当作一个四维流(空间三维加上时间一维)形来研究的,引力就是这个流形扭曲的结果。
当然,这些都是直观上的概念,其实流形并不需要依靠嵌入在一个“外围空间”而存在,稍微正式一点来说,一个 维的流形就是一个在任意点处局部同胚于(简单地说,就是正逆映射都是光滑的一一映射)欧氏空间 。
实际上,正是这种局部与欧氏空间的同胚给我们带来了很多好处,这使得我们在日常生活中许许多多的几何问题都可以使用简单的欧氏几何来解决,因为和地球的尺度比起来,我们的日常生活就算是一个很小的局部。
5.1.2 示例二
那么,除了地球这种简单的例子,实际应用中的数据,怎么知道它是不是一个流形呢?于是不妨又回归直观的感觉。再从球面说起,如果我们事先不知道球面的存在,那么球面上的点,其实就是三维欧氏空间上的点,可以用一个三元组来表示其坐标。但是和空间中的普通点不一样的是,它们允许出现的位置受到了一定的限制, 具体到球面,可以可以看一下它的参数方程:
可以看到,这些三维的坐标实际上是由两个变量 和 生成的,也可以说成是它的自由度是二,也正好对应了它是一个二维的流形。
5.1.3 示例三
有了这样的感觉之后,再来看流形学习里经常用到的人脸的例子,就很自然了。下图是Isomap 论文A Global Geometric Framework for Nonlinear Dimensionality Reduction(2000 science,1.2w被引)里的一个结果:

- 这里的图片来自同一张人脸,每张图片是 的灰度图,如果把位图按照列(或行)拼起来,就可以得到一个 维的向量,这样一来,每一张图片就可以看成是 维欧氏空间中的一个点
很显然,并不是 维空间中任意一个点都可以对应于一张人脸图片的,这就类似于球面的情形,我们可以假定所有可以是人脸的 维向量实际上分布在一个 维 的子空间中。
- 而特定到 Isomap 的人脸这个例子,实际上我们知道所有的 698 张图片是拍自同一个人脸(模型),不过是在不同的 pose 和光照下拍摄的,如果把 pose (上下和左右)当作两个自由度,而光照当作一个自由度,那么这些图片实际只有三个自由度,
换句话说,存在一个类似于球面一样的参数方程(当然,解析式是没法写出来的),给定一组参数(也就是上下、左右的 pose 和光照这三个值),就可以生成出对应的 4096 维的坐标来。这是一个嵌入在 4096 维欧氏空间中的一个 3 维流形。
- 上面的那张图就是 Isomap 将这个数据集从 4096 维映射到 3 维空间中,并显示了其中 2 维的结果,图中的小点就是每个人脸在这个二维空间中对应的坐标位置, 其中一些标红圈的点被选出来,并在旁边画上了该点对应的原始图片,可以很直观地看出这两个维度正好对应了 pose 的两个自由度平滑变化的结果
目前,把流形引入到机器学习领域来主要有两种用途:
- 一是将原来在欧氏空间中适用的算法加以改造,使得它工作在流形上,直接或间接地对流形的结构和性质加以利用
- 二是直接分析流形的结构,并试图将其映射到一个欧氏空间中,再在得到的结果上运用以前适用于欧氏空间的算法来进行学习
这里 Isomap 正巧是一个非常典型的例子,因为它实际上是通过“改造一种原本适用于欧氏空间的算法”,达到了 “将流形映射到一个欧氏空间” 的目的。 Isomap 所改造的这个方法叫做 Multidimensional Scaling (MDS) ,MDS 是一种降维方法,它的目的就是使得降维之后的点两两之间的距离尽量不变(也就是和在原是空间中对应的两个点之间的距离要差不多)。只是 MDS 是针对欧氏空间设计的,对于距离的计算也是使用欧氏距离来完成的。如果数据分布在一个流形上的话,欧氏距离就不适用了。
5.1.4 更多的思考
Isomap主要做了一件事情,就是把 MDS 中原始空间中距离的计算从欧氏距离换为了流形上的测地距离。当然,如果流形的结构事先不知道的话,这个距离是没法算的,于是 Isomap 通过将数据点连接起来构成一个邻接图 来离散地近似原来的流形,而测地距离也相应地通过图上的最短路径来近似了。如下图所示:

这个东西叫做Swiss Roll(瑞士卷),姑且把它看作一块卷起来的布好了:
- 图中两个标黑圈的点,如果通过外围欧氏空间中的欧氏距离来计算的话,会是挨得很近的点
- 可是在流形上它们实际上是距离很远的点:
- 红色的线是 Isomap 求出来的流形上的距离
可以想像,如果是原始的 MDS 的话,降维之后肯定会是很暴力地直接把它投影到二维空间中,完全无视流形结构,而 Isomap 则可以成功地将流形“展开”之后再做投影。

除了 Isomap 之外,Manifold Embedding 的算法还有很多很多,包括:
- Locally Linear Embedding
- Laplacian Eigenmaps
- Hessian Eigenmaps
- Local Tangent Space Alignment
- Semidefinite Embedding (Maximum Variance Unfolding) 等等等等
哪个好哪个坏也不好说,它们都各有特点,而且也各自有不少变种。
另一方面是改造现有算法使其适合流形结构甚至专门针对流形的特点来设计新的算法,比较典型的是 graph regularized semi-supervised learning 。简单地说,在 supervised learning 中,我们只能利用有 label 的数据,而(通常都会有很多的)没有 label 的数据则白白浪费掉。
在流形假设下,虽然这些数据没有 label ,但是仍然是可以有助于 Learn 出流形的结构的,而学出了流形结构之后实际上我们就是对原来的问题又多了一些认识,于是理所当然地期望能得到更好的结果!
当然,所有的这些都是基于同一个假设,那就是数据是分布在一个流形上的(部分算法可能会有稍微宽松一些的假设)
然而 real world 的数据,究竟哪些是分别在流形上的呢?这个却是很难说。不过,除了典型的 face 和 hand written digit 之外,大家也有把基于流形的算法直接用在诸如 text 看起来好像也流形没有什么关系的数据上,效果似乎也还不错。
话说回来,虽然和实际应用结合起来是非常重要的一个问题,但是也并不是决定性的,特别是对于搞理论方面的人来说。对于他们来说,其实也像是在做应用,不过是把数学里的东西应用到机器学习所研究的问题里来,而且其中关系错综复杂,图论、代数、拓扑、几何……仿佛是十八路诸侯齐聚一堂,所以让人总觉得要再花 500 年来恶补数学才行!