以下内容参考:数学传奇1——群星闪耀时
【图论的开创】
- 1736年, 时年29岁的莱昂哈德·欧拉(Leonhard Euler)向圣彼得堡科学院递交了题为《哥尼斯堡之七桥》的著名论文,长期悬而未决的哥尼斯堡七桥问题被彻底破解,该篇论文也被认为是标志图论创立的代表性文献。
【拉格朗日的降生】
- 同年,在遥远的亚平宁半岛上,约瑟夫-路易斯·拉格朗日(Joseph-Louis Lagrange)呱呱坠地。
- 拉格朗日的曾祖父是一名法国军官, 后移居至意大利都灵,与当地人结婚后诞下了拉格朗日的祖父
- 拉格朗日的父亲曾经负责掌管国王军队的金库,并在都灵的公共工程建设机构担任税务官。
- 拉格朗日本应过上优裕、富足的童年生活,无奈他的父亲却在经商过程中,不幸破产,致使家道中落
- 像其他望子成龙的父亲一样,拉格朗日的父亲一心想把自己的儿子培养成为一名律师, 但拉格朗日本人却对法律毫无兴趣。 事实上,在都灵大学就读时,拉格朗日最初对数学也不感兴趣。 直到17岁时,他读到了英国天文学家、数学家哈雷的介绍牛顿微积分的文章后,才逐渐迷上了数学。(证明数学从微积分开始才展现出无穷魅力)
- 拉格朗日早年的数学研究到底师承何方,至今成谜。或许也只有这样,才能符合一名旷世奇才理应无师自通这样的假设
【变分法的开创】
- 现在唯一确定的是,1755年,拉格朗日曾经给已经功成名就的欧拉写信讨论数学问题,彼时拉格朗日只有19岁。 在给欧拉的信中,拉格朗日发展了欧拉所开创的变分法,用纯分析的方法求变分极值。 欧拉在回信中对拉格朗日的成果大加称赞。这使拉格朗日在都灵声名大振,并让他在19岁时就当上了都灵皇家炮兵学校的教授。 欧拉和拉格朗日两人共同奠定了变分法的理论基础,相关成果后来被称为欧拉-拉格朗日方程, 这也标志着变分法的创立。
【拉格朗日德国任职】
- 八年后的1763年, 拉格朗日在巴黎游历期间,拉格朗日首次见到了达朗贝尔,这位前辈对拉格朗日也是青睐有加
- 两年后的1765年, 达朗贝尔在给普鲁士国王腓特烈大帝的信中热情赞扬拉格朗日,并建议在柏林给拉格朗日安排一个荣誉职位。 腓特烈大帝欣然应允,他认为在 “欧洲最伟大之王”的宫廷中理应有“欧洲最伟大的数学家”。
- 但拉格朗日出于对欧拉的尊敬,不愿与其争辉而婉拒。 闻听此事的欧拉毫不犹豫地展现了其豁达平易和高风亮节的一面,于次年主动离开柏林,远赴圣彼得堡。(欧拉1707年4月15日出生于瑞士的巴塞尔,1783年9月18日于俄国圣彼得堡去世。)
- 1766年3月, 达朗贝尔给欧拉写信说明情况,拉格朗日为欧拉的有意成全深深感动遂同意了前往柏林的邀约。
- 同年5月3日欧拉离开柏林后,拉格朗日正式接受普鲁士邀请,并于8月21日离开都灵来的柏林。在柏林期间,拉格朗日深受腓特烈大帝赏识。
- 腓特烈大帝还多次向拉格朗日传授健康规律之生活的益处。 拉格朗日深深地认可国王的建议,并在自己日后的研究和生活中努力践行这一金玉良言。健康规律的生活也间接提升了拉格朗日的工作效率, 在柏林期间,他完成了大量重要的研究成果,为一生研究中的鼎盛时期,其中多数论文都发表在柏林科学院和巴黎科学院的刊物中。(健康的身体有助于科研)
【拉格朗日法国任职】
- 1786年, 与拉格朗日交好的腓特烈大帝去世,一向重情重义的拉格朗日难免触景伤情, 越发想离开柏林这块伤心地。于是,在第二年,他决定接受巴黎科学院的邀请, 动身前往法国开始工作,并于7月底到达巴黎。
【一篇论文引发的血案】
- 1789年,法国大革命爆发,1793年, 革命政府决定以生于敌国为由逮捕拉格朗日,在化学家拉瓦锡的竭力保护之下,他才逃过一劫。
- 但厄运很快就降临到了拉瓦锡自己身上,而这个祸根早在十年之前就已经埋下。彼时,青年科学家马拉向法兰西科学院提交了一篇关于新燃烧理论的论文,希望可以加入科学院,但作为燃烧理论权威的拉瓦锡对这篇论文评价却很低, 导致马拉未能得偿所愿。法国大革命爆发后,雅克宾派掌权,已经成为雅克宾派领导人的马拉似乎对当年的事情仍然耿耿于怀。他在一本抨击旧制度下税务官的小册子中,专门指责曾经担任过税务官的拉瓦锡为了盘剥百姓,而向烟草上洒水增加重量。 但事实是拉瓦锡是为了防止烟草干燥才要求洒水,并且在洒水之前要称重,所有交易以干重为标准。 但在有意的煽动下,使得民众对税务官的仇恨旋即达到了顶峰
- 1794年拉瓦锡被捕,5月8日被定罪, 而且就在当天便同其他27名税务官一起被送上了断头台。在得知他的死讯之后,拉格朗日惋惜道:“他们只一瞬间就砍下了这颗头,但再过一百年也找不到像他那样杰出的脑袋了。 ”法国大革命结束后,拉瓦锡很快就被平冤昭雪,重新认定为无罪,但一切都为时已晚,这位被后世尊称为“近代化学之父”的伟大科学家已经永远地停止了思考。
【法国最著名两所学校的成立】
- 就在拉瓦锡去世的同一年, 巴黎成立了两个共和国最高学府:巴黎高等师范学院和巴黎综合理工大学
- 第二年, 拉格朗日开始于此两所高校任教,成为首批教授。小他十三岁的拉普拉斯也曾在这两所学校任教
- 二人先后培养出了多位杰出的数学家,其中就包括著名的傅立叶、泊松和柯西。
【拿破仑与数学家】
- 1799年11月, 政治强人拿破仑通过雾月政变登上历史舞台,结束了大革命以来各种恐怖局面轮番交替的形势。五年之后的1804年,拿破仑称帝,并建立法兰西第一帝国
- 军人出身的拿破仑,在主政时期,非常注重科学研究,尊重科学家。他认为:“一个国家只有数学蓬勃的发展,才能展现它国力的强大。数学的发展和至善与国家繁荣昌盛密切相关。”
- 彼时拿破仑与法国的多位数学大师都过从密切、相交甚笃。例如,他曾拜拉普拉斯为师,向其求教,还任命他为自己的内政部长。在更早的1798年,拿破仑远征埃及时,跟随其左右的傅立叶就曾因在军中表现突出而受到这位政治新星的赏识,在拿破仑掌权之后,他便任命傅立叶为格伦诺布尔省省长。
【痴迷热学的傅立叶】
- 1822年,傅立叶完成了他最重要的传世著作——《热传导的解析理论》。这本经典文献记述了他在研究热的传播时所创立的一套数学理论,也就是今日被称为“傅立叶分析”的重要数学方法
- 由于傅立叶极度痴迷热学,他认为热能包治百病, 于是在一个夏天,他关上了家中的门窗,穿上厚厚的衣服,坐在火炉边,于是他被活活热死了,1830年5月16日卒于法国巴黎
【左右逢源的拉普拉斯】
- 尽管这一时期法国历史风云巨变,但拉格朗日在政治上的表现却相当低调和沉郁。与此形成鲜明对比的是,他的同事、数学家和天文学家皮埃尔-西蒙·拉普拉斯(Pierre-Simon Laplace,1749~1827)却完全是另外一种风格。拉普拉斯不仅是数学上的大师,而且在政治上也左右逢源,无论谁上台,他都能始终屹立不倒。 拉普拉斯不仅担任过拿破仑的老师,并在其主政时期,当过六个星期的内政部长
- 拉普拉斯即使在席卷法国的政治变动中,包括拿破仑的兴起和衰落,也都没有使其受到显著影响,他甚至还在拿破仑皇帝时期和路易十八时期两度获颁爵位。 但不可否认他崇高的学术威望以及他将数学应用于军事问题的才能 在动荡的政治中保护了他
- 拉普拉斯在天文学和数学上的造诣极深,素有法国的牛顿之称。现在信号处理中普遍使用的拉普拉斯算子以及拉普拉斯变换都源于他的研究
【落落寡合的柯西】
- 奥古斯丁·路易·柯西(Augustin Louis Cauchy,1789~1857)法国著名数学家。数学中的很多定理和公式都以他的名字来称呼,例如我们熟知的柯西不等式、柯西中值定理,以及柯西收敛定理等等
- 柯西的父亲曾与当时法国的大数学家拉格朗日 与拉普拉斯交往密切。柯西少年时代的数学才华颇受这两位数学家的赞赏,并预言柯西日后必成大器
- 拉格朗日还建议他的父亲在他学好文科前不要学数学,其父因此加强了对柯西的文学教养,使他在诗歌方面也表现出很高的才华
- 柯西在纯数学和应用数学上的功力相当深厚,而在数学写作上,他是被认为在数量上仅次于欧拉的人,柯西一生大约写了八百篇论文,柯西全集有27卷之多
- 但作为久负盛名的科学泰斗,柯西落落寡合,也因此常常忽视青年学者的创造。其中最令人扼腕的是,十九世纪两大青年数学天才阿贝尔与伽罗瓦的开创性的论文手稿均因柯西而“失落”,造成群论晚问世约半个世纪
以下内容参考:被柯西坑了的两个天才数学家——阿贝尔和伽罗瓦
- 尼尔斯·亨利克·阿贝尔(Niels Henrik Abel)和埃瓦里斯特·伽罗瓦(Évariste Galois)并称为现代群论的创始人,而两个本来前途无量的年轻人,却都英年早逝,也常使后人唏嘘不已
【穷困潦倒的阿贝尔】
- 阿贝尔(Niels Henrik Abel,1802年8月5日─1829年 4月 6日)是十九世纪挪威出现的最伟大数学家。他的父亲是挪威一个小村庄的牧师,全家生活在穷困之中。 1820年,阿贝尔的父亲去世,照顾全家七口的重担突然交到还在读大学的阿贝尔的肩上
- 所幸他在读的奥斯陆大学的老师们都没放弃这位天才,他们一起资助了阿贝尔。阿贝尔勤奋自学,一边还花大量时间作研究,研究方向就包括了四次以上方程的求解。当时意大利的数学家鲁菲尼以五百多页的证明对一元五次方程求解做了论述, 并在柯西的推动下发展出了最初的置换群思想
- 年仅22岁的阿贝尔在置换群思想帮助下,发表了《一元五次方程没有代数一般解》的论文, 论文不仅以数万字的内容代替了鲁菲尼五百多页的证明,甚至还做了许多的补充。可是他实在付不起印刷的钱(说明发论文需要一定的财力基础), 于是数万字的论文稿再次被压缩成6页纸。阿贝尔将这6页论文寄往各地著名的数学家,希望能够得到肯定
- 阿贝尔苦苦等待,却得不到回复。所幸一年前发表的第一篇论文为他争取到了一笔政府的进修资助金。阿贝尔带上这笔钱,开始造访各地名家:
- 他在德国柏林拜访数学王子高斯时,高斯根本不相信阿贝尔能够用6页解答这个超级数学难题
- 阿贝尔随后来到巴黎,科学院秘书读了阿贝尔完整论文的引言,心里已经是感觉到了震惊异常,随即委托柯西审查。 可哪知道他一不留神就把阿贝尔推进了柯西的深坑里
- 前文提到的柯西在数学上特别高产,可谁都知道柯西除了高产还有一个特点:他写的论文都特别长。 为此数学杂志都不够位置刊登他的论文,他一怒之下办了专刊,专门发表自己的论文 (一般人写论文按篇算的,牛人写论文按本算的)。
- 当柯西拿到一份6页的论文时,他根本提不起重视的心情。他欢脱的带着稿件回了家,可事后竟然记不起放在什么地方!(说明有时候论文并不一定写得越多越好,不要忽视短小的论文)
- 阿贝尔在巴黎受尽了冷落:住着不便宜的公寓,论文的事迟迟没有回应,他处境越发难堪。最终政府的资助金用完了,阿贝尔无奈只得和亲戚借了一小笔钱,准备回挪威。而他不知道的是,此时他在巴黎不小心染上的感冒其实是肺结核
- 辗转回到挪威的阿贝尔,欠下不少钱债。他只好靠教书及收取大学的微薄津贴为生。一边维持生计还要一边偿还之前欠下的钱债
- 但他的穷困及病况并没有减低他对数学的热诚,他在这段期间写了大量的论文,主要是方程理论及椭圆函数,也就是有关阿贝尔方程和阿贝尔群的理论。他比雅可比(Jacobi)更快完全了椭圆函数的理论
- 还债和维持生计已经费尽全力,至于那总好不了的“感冒”已经无力治疗,阿贝尔的病逐渐严重起来。直至1829年4月6日凌晨,年仅27岁阿贝尔去世了, 他的未婚妻坚持不要他人之助照顾阿贝尔,“单独占有这最後的时刻”。直到阿贝尔去世前不久,人们才认识到他的价值
- 1828年,四名法国科学院院士上书给挪威国王,请他为阿贝尔提供合适的科学研究位置,在阿贝尔死後两天,阿贝尔的家人收到柏林大学数学教授的聘书, 可惜已经太迟,一代天才数学家已经在收到这消息前去世了。此后荣誉和褒奖接踵而来,1830年他和卡尔·雅可比共同获得法国科学院大奖
- 阿贝尔短暂的一生留下的著作是不多的,但他所作出的贡献却是巨大的,意义也是深远的,正如数学家埃尔米特所说:“阿贝尔所留下的思想,可供数学家们工作150年。”
【时运不济的伽罗瓦】
- 这时,另一位少年天才伽罗瓦在法国刚满18岁。他并不知道在远方的挪威,年轻的阿贝尔去世了。如果他知道 阿贝尔和他一样得出了四次以上的方程式的求解方法,他一定会感到天才之征途不孤独吧。 伽罗瓦比阿贝尔小9岁,他出生在一个善良、智慧的家庭
- 他的父亲在他4岁那年便竞选当上了市长,这让他的生活过的还算充裕。他在18岁这年, 通过自己的努力在代数方程领域取得巨大成果,正是伟大的群论。 似乎冥冥天意让伽罗瓦替阿贝尔完成未完的工作,群论完美的弥补了阿贝尔理论上的不足。这足以震撼世界的学术成果, 在呈交法国科学院之后,极巧的又碰上了柯西负责审阅
- 柯西则计划对伽罗瓦的研究成果在科学院举行一次全面的意见听取会。当他将伽罗瓦的研究成果带回家后,竟不小心连同摘要都弄丢, 原计划的听取会只得宣读了一篇他自己的论文。至于伽罗瓦的研究成果?已经因为意外“事故”无法宣读了。 看来伽罗瓦不只是接替了阿贝尔的代数工作,甚至还接替了阿贝尔的倒霉
- 伽罗瓦的家庭在这时遭遇了巨变,他的父亲在新一轮的选举中被对手暗中设局陷害,他父亲不堪其辱,选择了自杀。 这让知晓一切的伽罗瓦感到极度痛苦,父亲的冤死,让他选择了和共和主义站在一起,极端的政治观把伽罗瓦变得极爱作死。
- 1830年爆发了七月革命, 伽罗瓦所在的高等师范学院的校长将学生以禁止参与革命锁在高墙内。伽罗瓦此时政治的心那是熊熊燃烧,对校长的不满变成了校报上一篇言辞激烈的抨击文。校长也毫不客气的将伽罗瓦逐出校门。 之后激进伽罗瓦,两次被陷害入狱
- 备受不公的伽罗瓦在狱中他爱上了一个医生的女儿,伽罗瓦没想到的是,她居然有未婚夫,而她的未婚夫是一位和他一起入狱的军官。同伽罗瓦一样,这位军官也是一位激进的共和党人,伽罗瓦和对方争执,还主动提出要以决斗定胜负
- 等到伽罗瓦情绪平复的时候,才发现自己毫无胜算。怎么会和一个玩枪的行家决斗? 伽罗瓦来不及害怕:连夜写信给他的朋友们,将自己所有在数学上的结果写了下来,期间不停在纸的空白处写上“我没有时间”。 第二天,伽罗瓦如约赴战。子弹穿过了他的腹部,他最终死在了情敌手下,年仅21岁。至此,两个数学界的天才在三年里相继离世
- 伽罗瓦的一生才华横溢,无奈天妒英才。但令后人感佩的是,在各种磨难和波折下,在如此短暂而有限的生命里,他仍然不忘数学研究,用群论彻底解决了根式求解代数方程的问题,而且由此发展了一整套关于群和域的理论,后人们称之为伽罗瓦群和伽罗瓦理论
【群论的问世】
- 直到十数年后,其他的数学家找到了阿贝尔遗失在柯西家的手稿,也研究了伽罗瓦的信件。两位早逝的天才留下的财富让世人震惊群论推迟了半个世纪问世,最终在数学家刘维尔的推动下才让数学界承认这两位天才的杰作
- 此时的柯西已经年过四十,不再进行数学研究工作,只作为一个普通的教授教书育人。当他回忆当年,曾有两个不世的天才与他擦身而过。他余下人生教书育人也无法弥补这个巨大的遗憾了
- 柯西临死前曾说过,“人总是要死的,但是,他们的功绩永存”。说的是啊,阿贝尔和伽罗瓦都死了,他们的功绩差一点就永存在柯西家的角落里了
【总结】
- 法国数学大爆发的十八至十九世纪, 很难想象在那个短暂的时间和有限的空间中,居然汇集了如此之多的数学大师。 这其中的每个人放到任何国家无疑都是引领整个时代的学术巨擘
- 但历史的巧合让他们如此戏剧化的聚合到了一起,恰似那群星闪耀的时刻, 并由此也奠定了法国在数学领域的强大地位
- 自拉格朗日以来,法国数学的影响随着一代代门徒薪火相传而深远地扩散,至今不绝。
- 泊松的学生米歇尔·沙勒是让·加斯东·达布(Jean Gaston Darboux)的老师
- 达布的两个学生古萨(Édouard Goursat)和埃米尔·皮卡(Émile Picard)又是雅克·阿达马(Jacques Hadamard)的老师。信号处理中的沃尔什-阿达马变换 即源自阿达马的研究
- 阿达马的学生保罗·列维(Paul Lévy)在证明概率论里的中央极限定理过程中给出了著名的林德贝格-列维中央极限定理
- 列维的学生迈克尔·鲁文(Michel Loève)提出了著名的KL变换, 它的另外一个名字就是我们在降维中讨论的主成分分析(PCA)
- 鲁文的学生里奥·布瑞曼(Leo Breiman)则是著名的CART(Classification And Regression Tree)算法以及随机森林 的发明人。此外,他之于机器学习(特别是其中的集成学习领域)的重要贡献还包括Bagging以及关于Boosting的理论 探索
以下内容参考:如何理解 Graph Convolutional Network(GCN)?
对于图G=(V,E),其Laplacian矩阵定义为L=D−A,其中L是Laplacian矩阵,D是顶点的度矩阵(对角矩阵),对角线上元素依次为各个顶点的度,A是图的邻接矩阵。

常用的拉普拉斯矩阵有三种:
L=D−A定义的Laplacian 矩阵更专业的名称叫Combinatorial Laplacian
Lsys=D−1/2LD−1/2=I−D−21AD−21定义的叫Symmetric normalized Laplacian,很多GCN的论文中应用的是这种拉普拉斯矩阵
Lrw=D−1L定义的叫Random walk normalized Laplacian,
GCN的核心基于拉普拉斯矩阵的谱分解注:矩阵的谱分解,特征分解,对角化都是同一个概念,文献中对于这部分内容没有讲解太多。不是所有的矩阵都可以特征分解,其充要条件为n阶方阵存在n个线性无关的特征向量; 拉普拉斯矩阵是半正定对称矩阵(对称矩阵一定有n个线性无关的特征向量,半正定矩阵的特征值一定非负,对阵矩阵的特征向量相互正交,即所有特征向量构成的矩阵为正交矩阵。详细证明地址)。
因此,拉普拉斯矩阵一定可以谱分解,且分解后有特殊的形式。
拉普拉斯矩阵其谱分解为:
L=U⎣⎡λ1⋱λn⎦⎤U−1
其中U=(u1,u2,⋯,un),是列向量为单位特征向量的矩阵,即ul是列向量。
⎣⎡λ1⋱λn⎦⎤是n个特征值构成的对角阵。
U是正交矩阵,因此有UUT=E。
特征值分解可以写作:
L=U⎣⎡λ1⋱λn⎦⎤UT
注意:特征分解最右边的是特征矩阵的逆,只是拉普拉斯矩阵的性质才可以写成特征矩阵的转置。
传统的傅里叶变换定义为:
F(ω)=F[f(t)]=∫f(t)e−iωtdt
其本质是信号f(x)与基函数e−iωt的积分。解释如下:
首先需要知道如下1和2的知识点:
- 广义特征方程定义为:
AV=λV
其中A是一种变换,V是特征向量或特征函数(无穷维向量),Λ是特征值。
- Δ=∇2=散度∇∙梯度∇ 即:Laplace算子=n维欧几里德空间中的一个二阶微分算子= 梯度的散度 :参考资料
则类比1和2,下式:
Δe−iωt=∂t2∂2e−iωt=−ω2e−iωt
中e−iωt就是变换∇的特征函数,ω(频率)和特征函数密切相关。
推广到图上,用到了拉普拉斯矩阵(即离散拉普拉斯算子),来寻找拉普拉斯矩阵的特征向量。
设L是拉普拉斯矩阵,V是特征向量,则:
LV=λV
离散的积分就是内积,因此仿照上面定义图上的傅里叶变换:
F(λl)=f^(λl)=i=1∑Nf(i)ul∗(i)
f是Graph上的 N 维向量, f(i) 与Graph的顶点一一对应, ul(i)表示第 l 个特征向量的第 i 个分量。那么特征值(频率) λl 下的, f 的图傅里叶变换就是图上的每个节点与 λl 对应的特征向量 ul 进行内积运算。
利用矩阵乘法将Graph上的傅里叶变换推广到矩阵形式:
⎝⎜⎜⎜⎛f^(λ1)f^(λ2)⋮f^(λN)⎠⎟⎟⎟⎞=⎝⎜⎜⎜⎛u1(1)u2(1)⋮uN(1)u1(2)u2(2)⋮uN(2)……⋱…u1(N)u2(N)⋮uN(N)⎠⎟⎟⎟⎞⎝⎜⎜⎜⎛f(1)f(2)⋮f(N)⎠⎟⎟⎟⎞
f在图上的傅里叶变换为:f^=UTf(a)
传统的傅里叶逆变换是对频率ω求积分:
F−1[F(ω)]=2Π1∫F(ω)eiωtdω
迁移到Graph上变为对特征值λl求和:
f(i)=l=1∑Nf^(λl)ul(i)
利用矩阵乘法将Graph上的傅里叶逆变换推广到矩阵形式:
⎝⎜⎜⎜⎛f(1)f(2)⋮f(N)⎠⎟⎟⎟⎞=⎝⎜⎜⎜⎛u1(1)u1(2)⋮u1(N)u2(1)u2(2)⋮u2(N)……⋱…uN(1)uN(2)⋮uN(N)⎠⎟⎟⎟⎞⎝⎜⎜⎜⎛f^(λ1)f^(λ2)⋮f^(λN)⎠⎟⎟⎟⎞
即 f 在图上傅里叶逆变换的矩阵形式为:f=Uf^(b)
(f∗g)(t)=∫Rf(x)g(t−x)dx
详细请参考:
如何通俗地理解卷积?
离散卷积本质就是一种加权求和。CNN中的卷积本质上就是利用一个共享参数的过滤器(kernel),通过计算中心像素点以及相邻像素点的加权和来构成feature map实现空间特征的提取, 当然加权系数就是卷积核的权重系数。
那么卷积核的系数如何确定的呢?是随机化初值,然后根据误差函数通过反向传播梯度下降进行迭代优化。这是一个关键点,卷积核的参数通过优化求出才能实现特征提取的作用,GCN的理论很大一部分工作就是为了引入可以优化的卷积参数。
卷积定理的百度解释,公式如下:
f∗g=F−1{F{f}⋅F{g}}
公式的意义:即一个域相乘,相当于另一个域卷积;一个域卷积,相当于另一个域相乘。图域卷积相当于傅立叶域相乘,那先对图和卷积核做傅立叶变换后相乘,再傅立叶反变换回来,就得到了图域卷积。
更多资料其参考:
Laplacian算子
参考资料之——图卷积网络(GCN)新手村完全指南
f∗h=F−1[f^(ω)h^(ω)]=2Π1∫f^(ω)h^(ω)eiωtdω
类比到图上并把傅里叶变换的定义带入, f 与卷积核 h 在Graph上的卷积可按下列步骤求出:
根据上文公式(a),可得f的傅里叶变换为f^=UTf
卷积核 h 的傅里叶变换写成对角矩阵的形式即为:
⎝⎛h^(λ1)⋱h^(λn)⎠⎞
h^(λl)=∑i=1Nh(i)ul∗(i)是根据需要设计的卷积核 h (注意:这里自己设计的卷积和直接在频域设计,因此不需要傅里叶变换左乘矩阵U)在图上的傅里叶变换。
两者的傅立叶变换乘积即为:
⎝⎛h^(λ1)⋱h^(λn)⎠⎞UTf
再乘以U求两者傅立叶变换乘积的逆变换,则求出卷积:
(f∗h)G=U⎝⎛h^(λ1)⋱h^(λn)⎠⎞UTf
至此,上面这个公式对应原论文中公式(3)。
图卷积的卷积核参数就是diag(h^(λl))
Spectral Networks and Locally Connected Networks on Graphs中简单粗暴地把diag(h^(λl))变成了卷积核diag(θl),也就是:
youtput=σ(Ugθ(Λ)UTx)(3)
卷积核如下设计方式:
gθ(Λ)=⎝⎛θ1⋱θn⎠⎞
式(3)就是标准的第一代GCN中的层了,σ(⋅)是激活函数,Θ=(θ1,θ2,⋯,θn)是任意的参数,通过初始化赋值然后利用误差反向传播进行调整,x是图上上对应于每个顶点的特征向量(由特数据集提取特征构成的向量)。
第一代的参数方法存在着一些弊端:
- 每一次前向传播,都要计算U,diag(θl)和UT三者的矩阵乘积,特别是对于大规模的图,计算的代价较高,也就是论文中的O(n2)计算复杂度。
- 卷积核需要 n 个参数
Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering(该篇论文推导特别清晰,可以仔细阅读阅读)把diag(h^(λl))巧妙的设计成∑j=0Kαjλlj,即:
youtput=σ(Ugθ(Λ)UTx)(4)
gθ(Λ)=⎝⎜⎛∑j=0Kαjλ1j⋱∑j=0Kαjλnj⎠⎟⎞
上面的公式仿佛还什么都看不出来,下面利用矩阵乘法进行变换,来一探究竟。
⎝⎜⎛∑j=0Kαjλ1j⋱∑j=0Kαjλnj⎠⎟⎞=j=0∑KαjΛj
进而可以导出:
Uj=0∑KαjΛjUT=j=0∑KαjUΛjUT=j=0∑KαjLj
上式成立是因为L2=UΛUTUΛUT=UΛ2UT 且 UTU=E
(4)式就变成了:
youtput=σ(j=0∑KαjLjx)(5)
其中 (α1,α2,⋯,αK) 是任意的参数,通过初始化赋值然后利用误差反向传播进行调整。
式(5)所设计的卷积核其优点在于在于:
- 卷积核只有 K个参数,一般 K远小于 n,参数的复杂度被大大降低了。
- 矩阵变换后,神奇地发现不需要做特征分解了,直接用拉普拉斯矩阵L进行变换。然而由于要计算Lj,计算复杂度还是O(n2)(疑问)
- 卷积核具有很好的空间定位,并且K就是卷积核的感受野,也就是说每次卷积会将中心顶点K阶邻边上的点特征进行加权求和,K=1如下图:
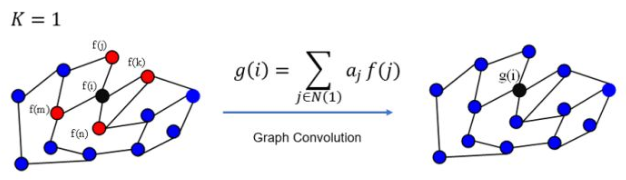
K=2如下图:

注:上图只是以一个顶点作为实例,GCN每一次卷积对所有的顶点都完成了图示的操作。
在第二代GCN中,L 是 n×n 的矩阵,所以Lj的计算还是O(n2) 复杂的, Wavelets on graphs via spectral graph theory提出了利用Chebyshev多项式拟合卷积核的方法,来降低计算复杂度。卷积核gθ(Λ)可以利用截断(truncated)的shifted Chebyshev多项式来逼近。
gθ(Λ)=k=0∑K−1θk′Tk(Λ~)(6)
θk′是Chebyshev多项式的系数。至此,上式公式即为原论文中公式(4)
Tk(Λ~)是取Λ~=2Λ/λmax−I的Chebyshev多项式,进行这个shift变换的原因是:Chebyshev多项式的输入要在[−1,1]之间。
由Chebyshev多项式的性质,可以得到如下的递推公式:
T0(Λ~)=IT1(Λ~)=Λ~Tk(Λ~)=2Λ~Tk−1(Λ~)−Tk−2(Λ~)(7)
上式等式两边分别左乘U,右乘UT,可得:
UT0(Λ~)UT=UIUT=I=T0(L~)UT1(Λ~)UT=UΛ~UT=L~=T1(L~)UTk(Λ~)UT=U2Λ~Tk−1(Λ~)UT−UTk−2(Λ~)UT=U2Λ~UTUTk−1(Λ~)UT−UTk−2(Λ~)UT=2L~Tk−1(L~)−Tk−2(L~)=Tk(L~)(8)
其中L~=2L/λmax−I,则卷积运算如下:
gθ⋆x=UgθU⊤x=Uk=0∑Kθk′Tk(Λ~)U⊤x=k=0∑Kθk′Tk(L~)x(9)
上式子就是原论文中的公式(5)。
我们注意到:
Tk(L~)x=2L~Tk−1(L~)x−Tk−2(L~)x∈Rn
其中x是n维的由每个顶点的特征构成的向量当然,也可以是 n×m 的特征矩阵,这时每个顶点都有 m 个特征,但是 m 通常远小于 n
这个时候不难发现:式(9)的运算不再有矩阵乘积了,只需要计算矩阵与向量的乘积即可。计算一次Tk(L~)x的复杂度是O(∣E∣),E是图中边的集合,则整个运算的复杂度是 O(K∣E∣) 。 当图是稀疏图(E≪2n(n−1))的时候,计算加速尤为明显,这个时候复杂度远低于 O(n2)
至此,原论文中公式(4)(5)以及算法简化的原因已解释清楚。
上面的讲述是GCN最基础的思路,很多论文中的GCN结构是在上述思路的基础上进行了一些简单数学变换。理解了上述内容,就可以做到“万变不离其宗”。
注:本部分参考地址——欧几里得空间的数学结构
欧几里得空间Rn是有序数组(称为点或向量) (x1,…,xn)形成的集合,其中xi为实数。在欧氏几何中,譬如平面几何与空间几何,我们可以计算两点之间的距离、多个向量的线性组合(向量加法与纯量乘法)、向量的长度,以及两个向量之间的夹角。
数学家将这些概念予以抽象化,并用公设化方式定义出不同的数学结构, 称为 空间。
在数学中,空间一词并不单独存在,我们可以称X是一个集合,但不讲X是一个空间。
粗浅地说,空间是一个赋予某种数学结构的集合,该数学结构决定空间的名称,
例如线性代数中大家熟悉的向量空间。
下面提到的欧氏空间Rn的一些数学结构,背后的目的是将有限维空间延伸至无限维空间, 其中最重要的一个特例是希尔伯特(Hilbert)空间。
我了进一步了解空间,下面举几个常见空间的例子:
度量空间(赋距空间,metric space)是一个集合(一般是非空集合),并赋予一距离函数,称为度量(度规,metric)。具体而言,度量空间是一个二元组(X,d),其中X为集合,度量d:X×X→[0,∞)为非负函数,满足
(M1) d(x,y)≥0(非负性)
(M2) d(x,y)=0⇔x=y(不可区分者的同一性)
(M3) d(x,y)=d(y,x)(对称性)
(M4) d(x,z)≤d(x,y)+d(y,z)(三角不等式)
公理(M4)是欧几里得几何中三角不等式的抽象公式化,这是一个非常重要的定义性质。度量空间的四个公理并不独立,(M1) 可由其他三个公理推得:
2d(x,y)=d(x,y)+d(y,x)≥d(x,x)=0。
给定集合X,度量d有许多合法的定义。例如,考虑X=Rn的两点x=(x1,…,xn)和y=(y1,…,yn),欧氏距离
d2(x,y)=(i=1∑n(xi−yi)2)1/2
或曼哈顿距离(Manhattan distance)
d1(x,y)=i=1∑n∣xi−yi∣
皆为集合X上的度量(有兴趣可自行验证d2和d1满足上述公理)。因此,即便(X,d2)和(X,d1)有相同的底层集(underlying set) X,两者是不同的度量空间。事实上,给定一个非空集合X,存在无限多个度量空间。譬如,若d是定义于X的一个度量,则dα(x,y)=αd(x,y),α>0,也是在X上的度量。
向量空间(vector space),或称线性空间(linear space),是一种代数结构,核心概念在于线性组合(合并向量加法与纯量乘法)。我们称V是一个布于体(域,field) F的向量空间,若x,y∈V与α∈F具备向量加法x+y和纯量乘法αx,并满足下列公理:
(V1) x+y=y+x(交换律)
(V2) x+(y+z)=(x+y)+z(结合律)
(V3)存在唯一的0∈V使得x+0=x
(V4)存在唯一的−x∈V使得x+(−x)=0
(V5) α(βx)=(αβ)x(结合律)
(V6) 1x=x
(V7) α(x+y)=αx+αy(分配律)
(V8) (α+β)x=αx+βx(分配律)
- 若F=R,则V称为实向量空间;
- 若F=C,则V称为复向量空间。
- 在线性代数中,欧氏空间Rn是最常见的一个向量空间, 其中的元素(x1,…,xn)构造一个n维实向量x。
- 线性映射(变换)则是向量空间中最重要的运算机制。设V和W为布于相同数系的向量空间,我们称T:V→W为一个线性映射,若任意x,y∈V和纯量α满足
T(x+y)T(αx)=T(x)+T(y)=αT(x).
线性映射出现在许多科学与工程领域, 这是我们对向量空间如此重视的原因。
注:本部分参考资料地址——线性代数里的代数结构
纯量加法的代数结构是阿贝尔群
考虑整数集Z(包含正整数、负整数与零),我们观察出任两个整数的加法运算满足以下五个性质:
-
加法具有封闭性,如果x和y属于Z,那么x+y也属于Z。
-
加法具有交换性,两整数之和与其计算位置无关,
x+y=y+x。
-
加法具有结合性,排序固定的三个整数之和与其执行加法的顺序无关,
(x+y)+z=x+(y+z)。
-
存在一整数0使得任何整数与其相加皆不改变,
x+0=0+x=x,
因此0也称为加法单位元。
-
任何加法都可以「回复」,意即每一整数皆存在逆元,如下:
x+(−x)=(−x)+x=0。
考虑正实数集R+,并以×表示一般的乘法运算:
x×y=xy。
明显地,正实数乘法满足封闭性、交换性与结合性。上例中0的角色被实数1所取代,1称为乘法单位元,满足下式:
x×1=1×x=x。
每一个正实数x的逆元为其倒数,因为
x×(x1)=(x1)×x=1。
上例整数Z的加法+与正实数R+的乘法×共同满足的五个性质即为阿贝尔群的定义。
正式定义: 给定一个集合G与二元运算∗,若满足上述五个性质,即封闭性、交换性、结合性,存在一运算单位元,且每一元素皆存在对应的逆元,我们便称(G,∗)为阿贝尔群。
如果二元运算∗除交换性外,满足其余四个性质, 则称为不可交换群或简称群。
不难验证(R,+)是一个群(也是阿贝尔群),但(R,×)不构成一个群,因为0不存在逆元,亦即不存在x使得0x=1。若将0剔除, 令R∗=R∖{0},则(R∗,×)为一个阿贝尔群。 明显地,若将实数R扩大为复数C,以上陈述仍然成立。
从有理数Q,实数R和复数C的性质如何归纳出体的定义呢?上述三种数系都具备加法与乘法运算:
- 对+而言,Q、R,C是阿贝尔群;
- 对×而言,Q∗,R∗,C∗(排除0所得的集合)也都是阿贝尔群;
- 剩下的工作只要再将这两种运算联系在一起,此即分配律:
α(x+y)=αx+αy(α+β)x=αx+βx
因此,我们归纳出体(域)的定义:一个体F是一个集合并赋予+和× 运算,而且(F,+)和(F∗,×)皆为阿贝尔群并满足分配律。
(如何理解布于一个体?)
布于一个体F(其中元素称为纯量)的一个向量空间(V,+,⋅)(其中元素称为向量)是一个加法阿贝尔群(即(V,+)是一个阿贝尔群),并赋予纯量α与向量x的乘法运算,简称为纯量乘法,其结果α⋅x为属于(V,+,⋅)的一个向量。以下向量空间记为V,并省略乘法符号⋅。为了使纯量乘法运算适当地配合既有的三种运算(F的加法,V的加法,F的乘法),还必须满足下列四个性质:
向量分配律:对于α,β∈F,x∈V,(α+β)x=αx+βx。
纯量分配律:对于α∈F,x,y∈V,α(x+y)=αx+αy。
结合律:对于α,β∈F,x∈V,(αβ)x=α(βx)。
纯量单位元:对于x∈V,存在1∈F,使得1x=x。
我们惊奇的发现:阿贝尔群(V,+)所满足的最后四个性质(扣除封闭性),再加上前述四个纯量乘法性质正是向量空间所必须满足的八个公理!
定义于度量空间的连续映射与定义于向量空间的线性映射可以合成为一个连续线性映射,具体的作法是将距离与长度引进向量空间,这个概念称为范数(norm)。对于一个布于体F的向量空间V,实函数∥x∥称为范数,其中x∈V,若下列性质成立:
(N1) ∥x∥≥0,∥x∥=0⇔x=0(非负性)
(N2) ∥αx∥=∣α∣⋅∥x∥,α∈F是任一纯量(均匀性)
(N3) ∥x+y∥≤∥x∥+∥y∥(三角不等式)
一个赋范向量空间(normed vector space)是二元组(V,∥⋅∥),其中V是一个向量空间,∥⋅∥是定义于V的一个范数。赋范向量空间(V,∥⋅∥)是一个度量空间:给定任意x,y∈V,
d(x,y)=∥x−y∥
是定义于V的一个度量。(N1)表明∥x−y∥≥0,且∥x−y∥=0等价于x=y,故满足(M1)与(M2)。设α=−1,由(N2)可得∥−(x−y)∥=∥x−y∥,满足(M3)。最后,由(N3)可得
∥x−y∥=∥x−z+z−y∥≤∥x−z∥+∥z−y∥,
此即(M4) 的三角不等式。
我们已经将欧氏几何中两点之间的距离、向量的线性组合,以及向量的长度等概念抽象化,最后剩下两向量之间的夹角,与此相关的概念是内积(inner product)和正交(orthogonality)。令V为复向量空间。内积是一个映射V×V→C,记为⟨x,y⟩,其中x,y∈V,并满足下列公理
(I1) ⟨x,x⟩≥0,⟨x,x⟩=0⇔x=0(非负性)
(I2) ⟨x,y+z⟩=⟨x,y⟩+⟨x,z⟩(可加性)
(I3) ⟨x,αy⟩=α⟨x,y⟩(均匀性)
(I4) ⟨x,y⟩=⟨y,x⟩(共轭对称性)
内积空间(inner product space)是一个二元组(V,⟨⋅,⋅⟩),其中V是向量空间,⟨⋅,⋅⟩是定义于V的内积。若⟨x,y⟩=0,我们说向量x和y是正交的。正交是内积空间中最重要的一个概念,正交使得内积空间拥有完善的几何性质,例如正交投影。内积空间(V,⟨⋅,⋅⟩)是一个赋范向量空间。我们可以证明
∥x∥=⟨x,x⟩1/2
是一个范数。不难证明∥x∥满足(N1)和(N2)。下面证明(N3)三角不等式成立。写出
∥x+y∥2=⟨x+y,x+y⟩=∥x∥2+⟨x,y⟩+⟨y,x⟩+∥y∥2=∥x∥2+2Re(⟨x,y⟩)+∥y∥2≤∥x∥2+2∣⟨x,y⟩∣+∥y∥2.
使用Schwarz不等式∣⟨x,y⟩∣≤∥x∥⋅∥y∥,可得
∥x+y∥2≤∥x∥2+2∥x∥⋅∥y∥+∥y∥2=(∥x∥+∥y∥)2。
如果一内积空间是完备度量空间,则称之为希尔伯特空间(即完备内积空间)。 因此,希尔伯特空间是定义了内积的巴拿赫空间。
最后我用一张图呈现欧氏空间Rn的数学结构阶层关系,X空间→Y空间表示X空间蕴含Y空间,各空间的核心概念总结于下:
度量空间:度量(距离)
向量空间:线性组合
赋范向量空间:范数(长度)
巴拿赫空间:范数与完备性
内积空间:内积(角度)
希尔伯特空间:内积与完备性

注:本部分参考地址——从几何空间到函数空间
基础线性代数课程常将讨论的向量空间局限于有限维几何向量空间Rn,下文通过问答方式,介绍如何将几何向量空间延伸推广至函数空间。
Q1:如果将n维实向量空间Rn扩展至无限维实向量空间R∞,此空间需满足何种条件始有利于实际应用?
A:很明显,R∞里的向量v包含无限多个元,如
v=⎣⎢⎢⎢⎡v1v2v3⋮⎦⎥⎥⎥⎤。
如果我们不对向量的元vi加入限制,那么此空间将过于庞大,反而令我们无所适从。对vi设限的最简单方式是透过向量v的长度,我们只对那些有限长度的向量感到兴趣,同时也希望几何向量空间的向量长度定义在此依然适用,亦即
∥v∥2=v12+v22+v32+⋯
这个无穷级数必须收敛至一有限数值,例如,无限维空间包含向量(1,21,31,⋯)T,但不含(1,1,1,⋯)T。
加入了有限向量长度的限制,此无限维空间仍符合向量空间的定义吗?是的。有限长度向量x与y之和其长度还是有限的,因为
∥x+y∥≤∥x∥+∥y∥,
而且纯量乘积ax的长度也是有限的。很容易验证向量空间的八个向量加法和纯量乘法性质依然成立,我们称之为希尔伯特(Hilbert)空间, 即一个保有一般几何性质的无限维实向量空间。希尔伯特空间也具有正交性质,我们说向量x和y是正交的,若其内积为零:
xTy=x1y1+x2y2+x3y3+⋯=0。
当然,歌西—舒瓦兹(Cauchy-Schwarz) 不等式也成立:
∣xTy∣≤∥x∥∥y∥。
Q2:希尔伯特空间与函数空间有什么关系?函数空间又该如何定义向量内积?
A:不需要受过专业数学训练,业余人士也可以看穿希尔伯特空间的外表伪装。用一个例子说明,考虑定义于区间0≤x≤2π的正弦函数f(x)=sinx,我们将函数f当作一个无限维向量,向量的各元即为连续区间内的函数值sinx。当向量的元是连续时,前述向量长度定义已不适用,各元平方和应该改为积分,如下:
∥f∥2=∫02π(f(x))2dx=∫02π(sinx)2dx=π。
此算式的意义重大,我们确实可以量测函数的长度,等于指出函数也是向量, 而仅包含有限长度的函数可以形成向量空间,因此希尔伯特空间变成了一个函数空间(function space)。
若f(x)=sinx,g(x)=cosx,运用同样的想法,将数列之和替换为积分可以产生两个函数的内积。
以⟨f,g⟩表示函数f和g的内积,例如:
⟨f,g⟩=∫02πf(x)g(x)dx=∫02πsinxcosxdx=0,
可知sinx与cosx正交。函数的长度可由内积求得,∥f∥2=⟨f,f⟩,舒瓦兹不等式则表示为∣⟨f,g⟩∣≤∥f∥∥g∥。
Q3:能否举个实用的函数空间例子,它包含哪些基底函数,如何产生座标?
A:最有名的例子是傅立叶级数(Fourier series),函数f(x)表示为正弦函数和余弦函数的展开式:
f(x)=a0+a1cosx+b1sinx+a2cos2x+b2sin2x+⋯
傅立叶级数的基底函数包含
1,cosx,sinx,cos2x,sin2x,⋯
傅立叶级数的系数即为参考此基底的座标,如要计算a1,可于等号两端同乘cosx,再从0积分至2π:
∫02πf(x)cosxdx=a0∫02πcosxdx+a1∫02π(cosx)2dx+b1∫02πsinxcosxdx+a2∫02πcos2xcosxdx+b2∫02πsin2xcosxdx+⋯
等号右边除了对应系数a1的项,其余所有项皆为零,有兴趣可自行验证正弦函数与余弦函数互为正交。因此,a1可由下式得到
a1=∫02π(cosx)2dx∫02πf(x)cosxdx=⟨cosx,cosx⟩⟨f,cosx⟩。
其他系数也可以使用同样方式求得,如欲计算b1,将cosx改为sinx,又如欲计算a2,则将cosx改为cos2x。
傅立叶级数的应用相当广泛:
- 一方面因为傅立叶选择了一组正交基底函数,f(x)的系数很容易得到
- 另一方面这组由正弦与余弦构成的基底能将问题转移至等价且适合发展理论分析的空间
至此,已完成了空间承上启下的讲解:
- 呈上:完成了上次报告没有解释的空间的定义
- 启下:引出了本次报告需要讲解的傅里叶变换的基础:傅里叶级数
后文参考资料包含以下链接:
如何通俗地理解傅立叶变换?
如何理解傅立叶级数公式?
从傅立叶级数到傅立叶变换
如何理解拉普拉斯变换?
让·巴普蒂斯·约瑟夫·傅立叶男爵(1768 -1830)猜测任意周期函数都可以写成三角函数之和。比如下面这个周期为2π的方波,可以用大量的正弦波的叠加来逼近:

从代数上看,傅立叶级数就是通过三角函数和常数项来叠加逼近周期为T的函数f(x):
f(x)=a0+n=1∑∞(ancos(T2πnx)+bnsin(T2πnx)),a0∈R
实际上是把f(x)当作了如下基的向量:
{1,cos(T2πnx),sin(T2πnx)}
那么上面的式子就可以解读为:
f(x)=基1下的坐标a0⋅1+n=1∑∞(对应基的坐标ancos(T2πnx)+对应基的坐标bnsin(T2πnx))
说具体点,比如刚才提到的,T=2π的方波f(x),可以初略的写作:
f(x)≈1+π4sin(x)
从几何上看,有那么一丁点相似:

我们可以认为:
f(x)≈1+π4sin(x)
此函数的基为:
{1,sin(x)}
则f(x)相当于向量:
(1,π4)
画到图上如下,注意坐标轴不是x,y,而是1,sin(x):
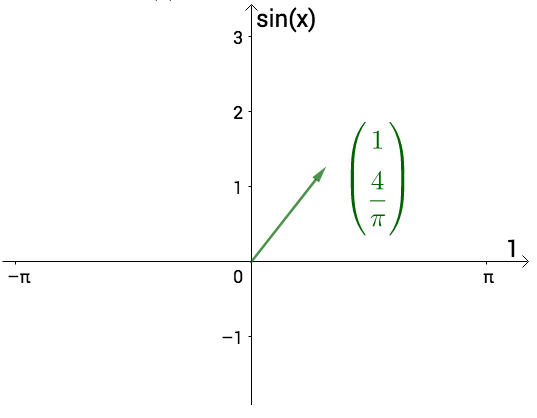
再增加几个三角函数:
$f(x)≈1+π4sin(x)+0sin(2x)+3π4sin(3x)+0sin(4x)+5π4sin(5x)4
从几何上看,肯定更接近了:
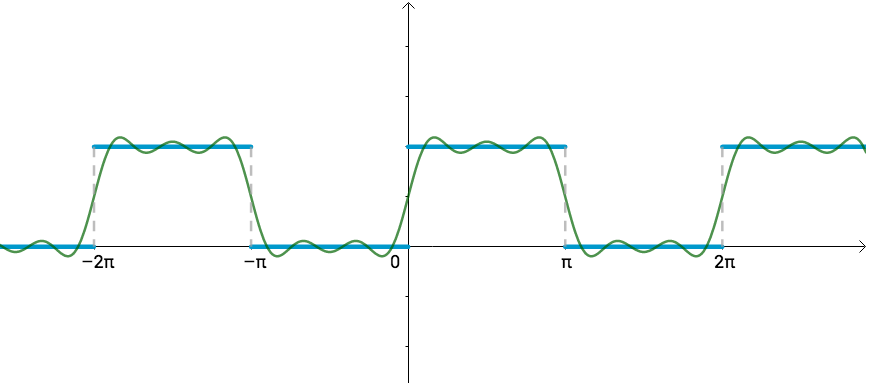
此时基为:
{1,sin(x),sin(2x),sin(3x),sin(4x),sin(5x)}
对应的向量为:
(1,π4,0,3π4,0,5π4)
六维的向量没有办法画图啊,没关系,数学家发明了一个频域图来表示这个向量:
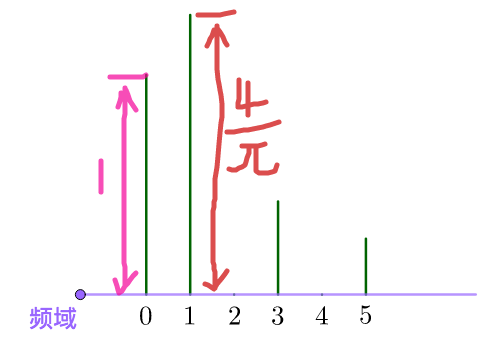
上图中的0,1,2,3,4,5分别代表了不同频率的正弦波函数,也就是之前的基:
0Hz⟺sin(0x)3Hz⟺sin(3x)⋯
而高度则代表在这个频率上的振幅,也就是这个基上的坐标分量。
这里举的例子只有正弦函数,余弦函数其实也需要这样一个频谱图,也就是需要两个频谱图。
原来的曲线图就称为时域图,往往把时域图和频域图画在一起,这样能较为完整的反映傅立叶级数:

不管时域、频域其实反映的都是同一个曲线,只是一个是用函数的观点,一个是用向量的观点。
当习惯了频域之后,会发现看到频域图,似乎就看到了傅立叶级数的展开:

非周期函数,比如下面这个函数可以写出傅立叶级数吗?

这并非一个周期函数,没有办法写出傅立叶级数。
不过可以变换一下思维,如果刚才的方波的周期:
T=2π→T=∞
那么就得到了这个函数:

在这样的思路下,就可以使用三角级数来逼近这个函数:
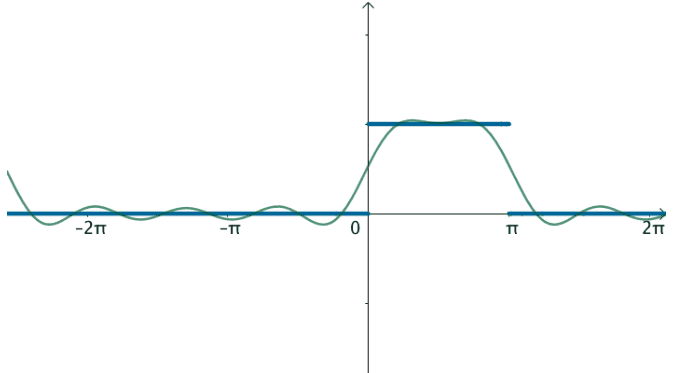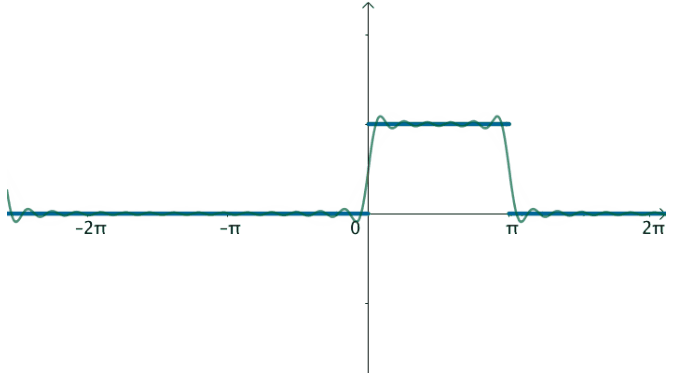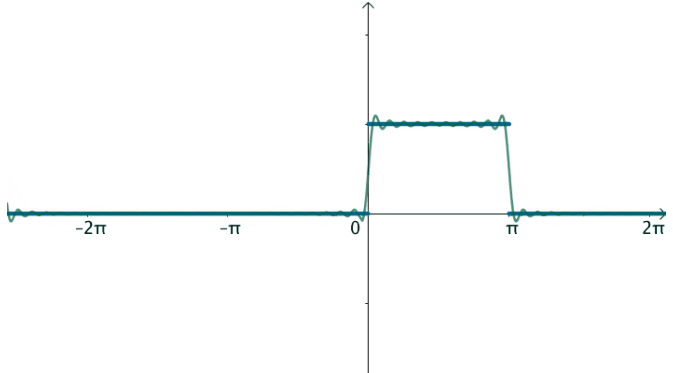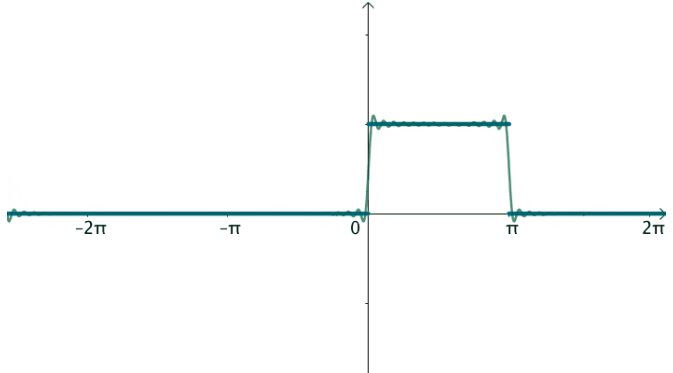
观察下频域,之前说了,对于周期为T的函数f(x),其基为:
{1,cos(T2πnx),sin(T2πnx)}
刚才举的方波T=2π,对应的基就为(没有余弦波):
{1,sin(x),sin(2x),sin(3x),sin(4x),sin(5x),⋯sin(nx)}
对应的频率就是:
{0Hz,1Hz,2Hz,3Hz,4Hz,5Hz,⋯nHz}
按照刚才的思路,如果T不断变大,比如让T=4π,对应的基就为(没有余弦波):
{1,sin(0.5x),sin(x),sin(1.5x),sin(2x),sin(2.5x),⋯sin(0.5nx)}
对应的频率就是:
{0Hz,0.5Hz,1Hz,1.5Hz,2Hz,2.5Hz,⋯0.5nHz}
和刚才相比,频率更加密集:

之前的方波的频域图,画了前50个频率,可以看到,随着T不断变大,这50个频率越来越集中:

可以想象,如果真的:
T=2π→T=∞
这些频率就会变得稠密,直至连续,变为一条频域曲线:

傅立叶变换就是,让T=∞,求出上面这根频域曲线。
之前说了,傅立叶级数是:
f(x)=a0+n=1∑∞(ancos(T2πnx)+bnsin(T2πnx)),a0∈R
这里有正弦波,也有余弦波,画频域图也不方便,通过欧拉公式,可以修改为复数形式:
f(x)=n=−∞∑∞cn⋅eiT2πnx
其中:
cn=T1∫x0x0+Tf(x)⋅eiT2πnxdx
复数形式也是向量,可以如下解读:
f(x)=n=−∞∑∞对应基的坐标cn⋅正交基eiT2πnx
不过cn是复数,不好画频域图,所以之前讲解全部采取的是三角级数。
周期推向无穷的时候可以得到:
f(x)=∑n=−∞∞cn⋅eiT2πnxT=∞}⟹f(x)=∫−∞∞F(ω)eiωxdω
上面简化了一下,用ω代表频率。
F(ω)大致是这么得到的:
cn=T1∫x0x0+Tf(x)⋅e−iT2πnxdxT=∞}⇒F(ω)=∫−∞∞f(x)e−iωxdx
F(ω)就是傅立叶变换,得到的就是频域曲线。
下面两者称为傅立叶变换对,可以相互转换:
f(x)⟺F(ω)
结论:看待同一个数学对象的两种形式,一个是函数,一个是向量。