回到主页
目录
- 目录
- SEMI-SUPERVISED CLASSIFICATION WITH GRAPH CONVOLUTIONAL NETWORKS
SEMI-SUPERVISED CLASSIFICATION WITH GRAPH CONVOLUTIONAL NETWORKS
Abstract:
- 本文提出了一种基于卷积神经网络的半监督学习方法,该方法是一种高效的半监督学习方法。
- 选择了谱图卷积的局部一阶近的卷积结构
- 模型在图形边的数量上线性扩展,并学习了编码局部图结构和节点特征的隐层表示
- 在引文网络和知识图数据集上的大量实验表明,本文方法和相关方法相比具有显著的优势
1. INTRODUCTION(介绍)
考虑分类一个图结构中的节点的问题,标签仅在节点中部分子集中已知。该问题即为基于图的半监督学习问题,其中的标签信息通过某种形式的显式基于图的正则化对图进行平滑(4篇论文)得到。例如:在损失函数中使用一个图拉普拉斯正则化项:
其中:
- 为监督损失,即图中有标签的部分
- 是可以选择类神经网络的可微函数
- 是权重因子,是由节点特征向量组成的矩阵
- 代表个节点,边为的无向图的非标准化图拉普拉斯行列式。其中:
- 代表邻接矩阵
- 代表度矩阵。
方程的公式(1)依赖于图中连接的节点可能共享相同标签的假设。然而,这种假设可能会限制建模能力,因为图边不一定需要编码节点相似性,但可能包含附加信息。
而本文工作直接使用神经网络模型对图形结构进行编码,在有监督的目标上训练,从而避免了损失函数中显式的基于图的正则化。图的邻接矩阵上的条件将允许模型从有监督的损耗中分配梯度信息,并使其能够获得有标签和无标签节点的表示形式。
本文贡献两点:
- 首先,针对直接作用于图上的神经网络模型,提出了一种简单、性能良好的分层传播规则,并从谱图卷积的一阶近似出发给出了该规则的推导过程
- 其次,我们演示了这种形式的基于图的神经网络模型如何能够用于快速和可伸缩的半监督分类节点的图
对大量数据集的实验表明,与目前最先进的半监督学习方法相比,本文的模型在分类精度和效率方面都有优势。
2. FAST APPROXIMATE CONVOLUTIONS ON GRAPHS(图上的快速近似卷积)
在本节中,我们提供了一个特定的基于图的神经网络模型的理论动机,该模型将贯穿后文。我们考虑一个具有以下逐层传播规则的多层图卷积网络(GCN):
其中表示插入自循环的邻接矩阵,是它的对角度矩阵。
下面,我们证明了这种传播规则的形式可以通过图上局部谱滤波器的一阶近似得到。
2.1 SPECTRAL GRAPH CONVOLUTIONS(谱图卷积)
我们把图上的谱卷积定义为在傅里叶域上信号(每个节点上都是标量)和以为参数的滤波器的乘法,即:
- 是归一化图拉普拉斯矩阵的特征向量矩阵,其中是其特征值组成的对角矩阵
- 是的图傅里叶变换矩阵
- 可以将理解成的特征值函数,即。
- 等式计算复杂度较高,因为与特征向量矩阵相乘的时间复杂度是
- 特别的,对于大型的图来说,一开始计算其矩阵特征值分解的数值就极其耗时,为了解决该问题,论文Hammond et al. (2011)中说明能够很好的被切比雪夫多项式的前个截断展开近似:
其中从新调整的,代表的最大特征值。现在是一个切比雪夫系数向量。切比雪夫多项式递归的定义为,其中。读者可以在论文Hammond et al. (2011)中找到更详细的讨论。
回到带有滤波器的信号的卷积的定义,现在可得:
其中。通过可验证该式。注意,这个表达式现在是阶局部化的,因为它是拉普拉斯多项式中的一个阶多项式,也就是说,它只依赖于距离中心节点(阶邻域)最大步的节点。等式(5)的复杂度是,即与边数线性相关。
(Defferrard et al., 2016)Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering使用这个局部卷积在图上定义卷积神经网络。
2.2 LAYER-WISE LINEAR MODEL(层级线性模型)
基于图卷积的神经网络模型可以通过将多个卷积层叠加成式(5)的形式,每一层叠加一个逐点非线性操作。现在,假设我们将逐层卷积运算限制为(见式5),即一个基于的线性函数,也就是图拉普拉斯谱上的一个线性函数。
在这个GCN的线性公式中,进一步近似,我们可以预期神经网络参数在训练过程中会适应这种尺度的变化。在这种近似下式(5)可以简化为:
其中有两个自由参数和。过滤器参数可以在整个图中共享。这种形式的滤波器的连续应用有效地对一个节点的阶邻域进行卷积,其中为神经网络模型中连续滤波操作或卷积层的个数。
在实践中,进一步限制参数的数量以解决过拟合问题,并将每层操作的数量(如矩阵乘法)最小化可能得到有益的结果。这就剩下了下面的表达式:
其中的单一参数。注意的特征值的范围变为。因此,当在深度神经网络模型中使用该算子时,重复使用该算子会导致数值不稳定性和爆炸/消失梯度。为了缓解这个问题,我们引入了以下重正态化技巧,其中 并且
可以把这个定义推广到具有个输入通道的信号上。滤波函数如下:
该筛选操作的时间复杂度为。
3. SEMI-SUPERVISED NODE CLASSIFICATION(半监督节点分类)
引入了一个简单而灵活的模型来有效地在图上传播信息,现在可以回到半监督节点分类问题。
3.1 EXAMPLE(样例)
- 考虑了一个两层的GCN来对一个具有对称邻接矩阵(二进制或加权)的图进行半监督节点分类
- 首先在预处理步骤中计算
- 然后我们的正向模型采用简单的形式
其中,是一个具有特征映射的隐含层的输入-隐藏权矩阵。是一个隐藏到输出的权重矩阵。
4. RELATED WORK(相关工作)
略
5. EXPERIMENTS(实验)
我们通过一系列实验对模型进行了测试:
- 引文网络中的半监督文档分类
- 从知识图中提取的二分图中的半监督实体分类
- 各种图传播模型的评估以及随机图的运行时分析
5.1 DATASETS(数据集)
本文使用Yang等人(2016)的实验设置。数据集统计汇总如表1所示。在引文网络数据集中:
- Citeseer、Cora和Pubmed (Sen et al., 2008)节点是文档,边是引文链接
- 标号率表示用于训练的标号节点数除以每个数据集中的节点总数。
- NELL(Carlson et al., 2010;Yang et al., 2016)是从一个包含55864个关系节点和9891个实体节点的知识图中提取的二分图数据集
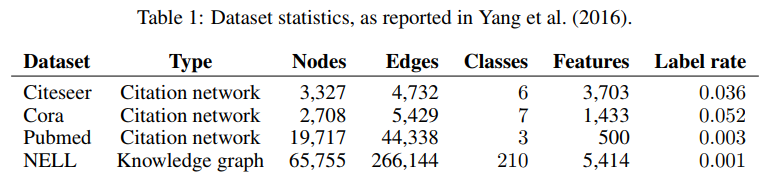
引文网络 我们考虑了三种引文网络数据集:Citeseer、Cora和Pubmed (Sen et al., 2008)
- 这些数据集包含每个文档的稀疏袋式单词特征向量和文档之间的引用链接列表
- 将引用链接视为(无向)边,并构造一个二元对称邻接矩阵
- 每个文档都有一个类标签
- 对于训练,每节课只使用20个标签,但是使用所有的特征向量。
NELL NELL是从引入的知识图中提取的数据集(Carlson et al., 2010)
- 知识图是一组与有向的、有标记的边(关系)连接的实体
- 遵循Yang et al.(2016)中描述的预处理方案:
- 为每个实体对分配单独的关系节点和,作为和
- 实体节点由稀疏特征向量描述。通过为每个关系节点分配一个独热表示
- 扩展了NELL中的特征数量,有效地得到每个节点的61,278个模糊稀疏特征向量
- 如果节点和之间存在一条或多条边,我们通过设置条目,从这个图中构造一个二元对称邻接矩阵
随机图 模拟各种大小的随机图数据集,用于测量每个历元的训练时间
- 对于一个有N个节点的数据集,我们创建一个随机图,随机分配2N条边
- 将单位矩阵作为输入特征矩阵,从而隐式地采用一种无特征的方法
- 模型只知道每个节点的身份,由唯一的一个热向量指定
- 为每个节点添加哑标签
5.2 EXPERIMENTAL SET-UP(实验设置)
- 除非另有说明,否则我们将按照3.1节的描述训练一个双层GCN,并在一个包含1000个标记示例的测试集上评估预测精度
- 提供额外的实验中使用更深的模型见附录b
- 不使用验证集标签进行训练
对于引文网络数据集
- 只优化Cora上的超参数,并对Citeseer和Pubmed使用相同的一组参数
- 使用Adam (Kingma &Ba, 2015),学习率为0.01
- 早停窗口大小为10,即验证损失连续10个周期不减少,则停止训练
- 使用(Glorot & Bengio 2010)中描述的初始化来初始化权重和相应的输入特征向量并进行归一化
- 在随机图数据集上,我们使用32个单位的隐藏层大小,并省略正则化(即既不删除也不用L2正则化)
5.3 BASELINES(基线)
- 与很多论文的基线方法进行了比较,即...
6. RESULTS(结果)
结果如表2所示。报告的数字表示分类精度(以百分比表示):
- 对于ICA,我们报告了随机节点顺序下100次运行的平均精度
- 所有其他基线方法的结果均取自Planetoid论文(Yang et al., 2016)
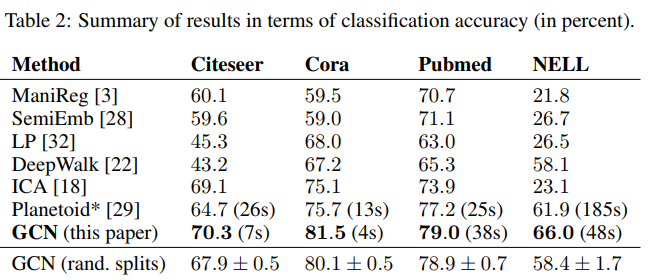
可以看出,本文方法结果最好
6.2 EVALUATION OF PROPAGATION MODEL(评价传播模型)
- 比较了本文提出的在引文网络数据集上的每层传播模型的不同变体
- 遵循上一节描述的实验设置
- 结果如表3所示:原始GCN模型的传播模型用重正态化技巧表示(粗体)。在所有其他情况下,这两个神经网络层的传播模型都替换为在传播模型下指定的模型。
- 结果表示使用随机权重矩阵初始化的100次重复运行的平均分类精度

6.3 TRAINING TIME PER EPOCH(每批的训练时间)

- 上图显示了模拟随机图上100批的平均训练时间(前向传递、交叉熵计算、后向传递)的结果,以秒为单位
- 这些实验中使用的随机图数据集的详细描述见5.1节
- 比较了在TensorFlow中GPU和仅cpu实现上的结果(Abadi等,2015)。图2总结了结果。
7. DISCUSSION(讨论)
略
8. ACKNOWLEDGMENTS(致谢)
感谢Tony Thrall和Isabella Barbier设计了该工作的数据采集。